
Wir haben uns damit abgefunden, dass Geheimdienste, Onlineservices und Co. mehr über uns herausfinden können, als uns bewusst und lieb ist. Es ist möglich, aus unserem vergangenen Verhalten abzuleiten, welche Filme wir mögen, welche Produkte uns interessieren, welche Meinung wir zu bestimmten Themen haben, ob wir uns in einer festen Beziehung befinden, …
Aber kann man auch herausfinden, welchen Charakter wir haben? Schwer vorstellbar, doch vielleicht indem man den Inhalt unserer Posts auf Social Networks und die Art unserer gekauften Produkte analysiert? Menschlichen Beobachtern ist das ohne Zweifel möglich, in den meisten Fällen sogar wenn man in Betracht zieht, dass man sich vielleicht bei seinem Onlineprofil nicht ganz natürlich darstellt und ein wenig das eigene Ideal von sich präsentieren mag. Studien haben gezeigt, dass wir unbewusst automatisch Persönlichkeitsmerkmale aus Profilinformationen ableiten und darüber oft vergessen, anhand welcher konkreter Informationen wir zu dem Ergebnis gekommen sind. Das heißt, wir erinnern uns anzunehmen, dass eine Person vermutlich eher extrovertiert ist vergessen aber, dass sie ausschweifende Partyfotos gepostet hat, die uns ursprünglich zu dieser Annahme gebracht hatten.
Aber wie bringt man Maschinen bei, ob wir zu Wutausbrüchen neigen oder eher der Ja-Sager-Typ sind? Ausgangspunkt für viele Versuche auf diesem Feld sind unsere Smartphones. Kein Wunder, denn die Geräte beherbergen oftmals das halbe Leben des Besitzers: Telefonate, Adressbücher, Termine, Fotos, Musik, Apps und dazu noch Ortsdaten, Kommunikationsprofile und ein ganzer Schatz weiterer Datenschnipsel.

Computer brauchen Modelle
Aber bevor ein Digitalgehirn diese nutzen kann, muss ein Modell gebildet werden, das auch ein Algorithmus verstehen kann. Im Bereich der Persönlichkeitspsychologie trifft man oft auf das „Big Five“-Modell. Es teilt Charakterzüge in fünf Klassen ein:
- Neurotizismus: Unterschiede im Erleben von negativen Erfahrungen, vor allem hinsichtlich emotionaler Stabilität. Angst, Nervosität, Anspannung, Trauer, Unsicherheit und Verlegenheit sind Anzeichen für eine neurotische Persönlichkeit.
- Extraversion: Begeisterungsfähigkeit und Geselligkeit
- Gewissenhaftigkeit: organisiertes Handeln, Selbstdisziplin und Ehrgeiz
- Verträglichkeit: Verständnis und Rücksichtnahme anderen Personen gegenüber, kooperatives Verhalten und Vertrauen
- Offenheit: Interesse an neuen Erfahrungen und Eindrücken, Kreativität und Unkonventionalität
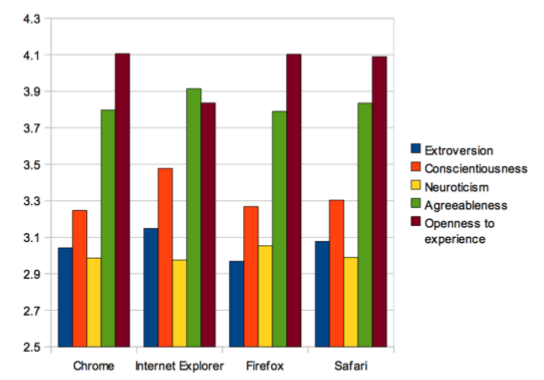 „Big Five“ dient bereits seit den 30ern als Persönlichkeitsmodell und hat sich als Standard etabliert. Seitdem wird es in einer Vielzahl von Studien verwendet. Doch nicht nur der Wissenschaftswelt leisten die „Big Five“ gute Dienste, auch die Analysten von GCHQ nutzen das System zur Kategorisierung, wie im Zuge der Veröffentlichung von Squeaky Dolphin bekannt wurde. Dort ließ sich auch die Erkenntnis nachlesen, wie allein der verwendete Browser in gewissem Maß Hinweise auf die Person geben kann – Nutzer des Internet Explorer neigten demnach am ehesten zu einer verträglichen, konformen Persönlichkeit.
„Big Five“ dient bereits seit den 30ern als Persönlichkeitsmodell und hat sich als Standard etabliert. Seitdem wird es in einer Vielzahl von Studien verwendet. Doch nicht nur der Wissenschaftswelt leisten die „Big Five“ gute Dienste, auch die Analysten von GCHQ nutzen das System zur Kategorisierung, wie im Zuge der Veröffentlichung von Squeaky Dolphin bekannt wurde. Dort ließ sich auch die Erkenntnis nachlesen, wie allein der verwendete Browser in gewissem Maß Hinweise auf die Person geben kann – Nutzer des Internet Explorer neigten demnach am ehesten zu einer verträglichen, konformen Persönlichkeit.
Smartphones haben alles, was man braucht…
Ein Ansatz, von der Smartphonenutzung auf die fünf Persönlichkeitszüge zu schließen, geht über die App-Nutzung. Eine Arbeit von Forschern aus der Schweiz stützt sich dabei auf den selben Datensatz, der uns bereits bei der Ortsvorhersage begegnet ist. Es handelt sich dabei um eine Datenbank, in der GPS-Position, die IDs der Funkzellen, bei denen das Telefon registriert war, eventuell bekannte WLAN-Access-Points, Anruf- und SMS-Metadaten, Bluetooth-Informationen und Logs zur Nutzung von Anwendungen von 200 Einzelpersonen gesammelt wurden. Die Daten wurden von 2009 – 2011 durch Nokia in der Lausanne Data Collection Campaign gesammelt und zur Grundlage vieler Publikationen zu Verhaltensstudien, sozialen Verbindungen und zur Positionsvorhersage.
 Aus den Daten ergab sich, dass die Anwendungsnutzung maßgeblich bei der Einschätzung der Persönlichkeit behilflich sein kann, und beispielsweise introvertierte Persönlichkeiten seltener das Internet nutzten wohingegen Neurotizität und Gewissenhaftigkeit oftmals mit häufiger Nutzung des Mailprogramms einhergingen. Andere Faktoren und Metadaten spielten auch eine Rolle, die Anwendungsnutzung jedoch war am Signifikantesten.
Aus den Daten ergab sich, dass die Anwendungsnutzung maßgeblich bei der Einschätzung der Persönlichkeit behilflich sein kann, und beispielsweise introvertierte Persönlichkeiten seltener das Internet nutzten wohingegen Neurotizität und Gewissenhaftigkeit oftmals mit häufiger Nutzung des Mailprogramms einhergingen. Andere Faktoren und Metadaten spielten auch eine Rolle, die Anwendungsnutzung jedoch war am Signifikantesten.
… Telekommunikationsanbieter auch
Eine neue, bittere Erkenntnis zeigt nun: Eigentlich braucht man die Zusatzinfos zur App-Nutzung nicht. Metadaten reichen schon, um unsere Charakterzüge grob zu bestimmen. Eine Gruppe französischer und amerikanischer Forscher aus dem MIT Media Lab hat analysiert, wie man vom Kommunikationsverhalten einer Person auf deren Charakter schließen kann. Aus Dazu zog die Gruppe Daten aus fünf Kategorien heran:
- Einfache Daten, z.B. die Zahl der Anrufe
- Nutzerverhalten wie die Anzahl der gewählten Nummern und durchschnittliche Antwortzeiten
- Ortsinformationen
- Regelmäßigkeit der Anrufe
- Verhältnis zwischen der Anzahl gespeicherter Kontakte und der Interaktionsfrequenz
Ziel der Untersuchungen war es, automatisch zu klassifizieren, ob die oben aufgeführten Eigenschaften bei der jeweiligen Personen in hoher, niedriger oder durchschnittlicher Ausprägung vorlagen. Als Methode zur Klassifikation wurden Support Vector Machines genutzt, die uns bereits im zweiten Teil der Serie begegnet sind. Kurze Auffrischung: Sie versuchen, durch Vektoren beschriebene Punkte mit einer Trennlinie in zwei Klassen einzuteilen, sodass zwischen den Klassen ein möglichst breiter Trennstreifen liegt.
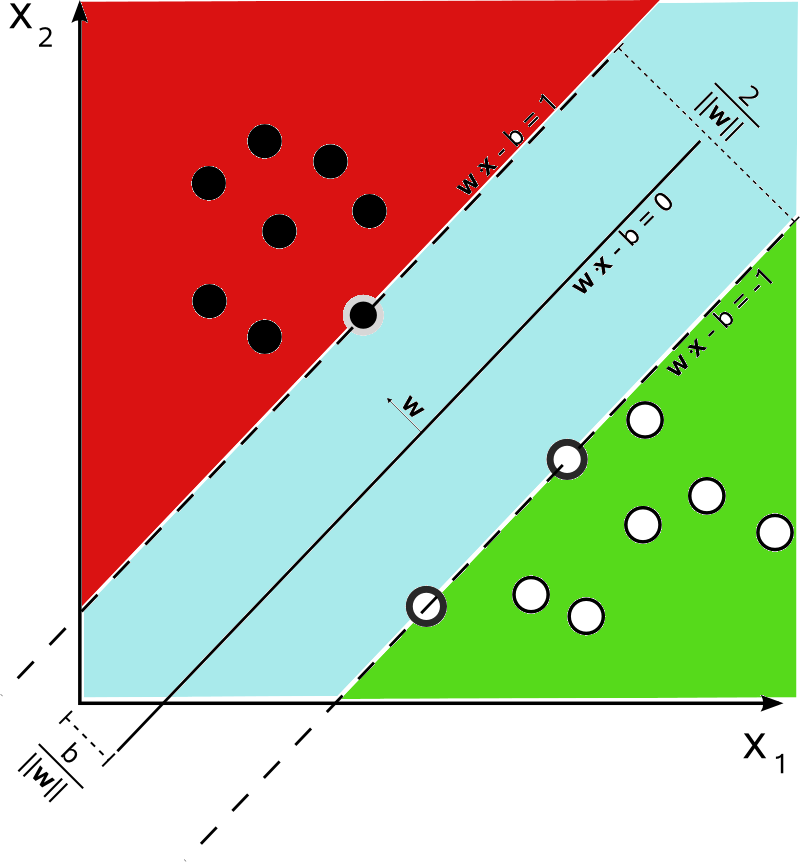 Die SVMs repräsentieren je einen der Charakterzüge. Es wurden also 5 verschiedene SVMs erstellt, die jede Eigenschaft in „stark“, „normal“ oder „wenig“ ausgeprägt einteilten. Man mag sich nun zu Recht fragen, wie auf einmal drei Kategorien unterschieden werden können, wo es doch bei SVMs eigentlich nur eine Unterscheidung zwischen zweien gibt. Es gibt verschiedene Möglichkeiten, mehr als 2 Kategorien durch SVMs zu unterscheiden. Beispielsweise je zwei Kategorien gegeneinander zu testen – „stark-normal“, „normal-wenig“, „stark-wenig“ – und nach Mehrheit zu entscheiden oder eine Kategorie gegen alle anderen. Das intuitivste hier ist aber, sich den Abstand des Testpunktes von der Trennlinie zu Rate zu ziehen. Denn da ein Großteil der Bevölkerung zur mittleren Ausprägung eines bestimmten Persönlichkeitszuges neigt, ist es sinnvoll, nur die Fälle zum Trainieren des Klassifikators zu nutzen, bei denen eine eindeutige Tendenz vorhanden ist. So wird der Trennbereich zwischen den zwei Gruppen „stark“ und „wenig“ größer. Alle Personen, die also in diesem Trennbereich liegen, können als „normal“ ausgeprägt angenommen werden.
Die SVMs repräsentieren je einen der Charakterzüge. Es wurden also 5 verschiedene SVMs erstellt, die jede Eigenschaft in „stark“, „normal“ oder „wenig“ ausgeprägt einteilten. Man mag sich nun zu Recht fragen, wie auf einmal drei Kategorien unterschieden werden können, wo es doch bei SVMs eigentlich nur eine Unterscheidung zwischen zweien gibt. Es gibt verschiedene Möglichkeiten, mehr als 2 Kategorien durch SVMs zu unterscheiden. Beispielsweise je zwei Kategorien gegeneinander zu testen – „stark-normal“, „normal-wenig“, „stark-wenig“ – und nach Mehrheit zu entscheiden oder eine Kategorie gegen alle anderen. Das intuitivste hier ist aber, sich den Abstand des Testpunktes von der Trennlinie zu Rate zu ziehen. Denn da ein Großteil der Bevölkerung zur mittleren Ausprägung eines bestimmten Persönlichkeitszuges neigt, ist es sinnvoll, nur die Fälle zum Trainieren des Klassifikators zu nutzen, bei denen eine eindeutige Tendenz vorhanden ist. So wird der Trennbereich zwischen den zwei Gruppen „stark“ und „wenig“ größer. Alle Personen, die also in diesem Trennbereich liegen, können als „normal“ ausgeprägt angenommen werden.
Als „Punkte“, die zu den benötigten Vektoren gehören, dienen die ermittelten Werte, beispielsweise die durchschnittliche Zeit, die ein Nutzer zum Beantworten einer SMS benötigt oder der maximale Radius, in dem sich die Person innerhalb eines Tages bewegt. Insgesamt wurden bei den Versuchen fast 40 verschiedene Angaben über eine Person erfasst, aber nachvollziehbarerweise ist nicht jeder Wert gleich wichtig. Deshalb entfernten die Forscher nach und nach Werte aus den Vektoren der jeweiligen SVM, wenn diese das Ergebnis nicht verschlechterten oder durch ihre Abwesenheit sogar verbesserten, bis das Entfernen weiterer Werte das Ergebnis beeinträchtigt hätte. Dadurch bildeten sich auch interessante Erkenntnisse dazu, welche Werte bei der Bestimmung welcher Persönlichkeitszüge am relevantesten sind.
Beispielweise bestand eine starke Korrelation zwischen der Zeitspanne zwischen Anrufen und Textnachrichten und der Gewissenhaftigkeit der Teilnehmer. Für die Beurteilung von Offenheit war es ausschlaggebend, zu wissen wieviel Prozent der Kommunikationsvorgänge von der jeweiligen Person selbst initiiert wurden. Andere Zusammenhänge waren überraschend: Für die Einschätzung der Neurotizität spielte den Ergebnissen zufolge die täglich zurückgelegte Entfernung und die Aufenthaltsorte eine Rolle.

Zufall oder echter Zusammenhang?
Apropos Korrelation, Relevanz und Signifikanz… Manchmal stellt sich die berechtigte Frage, ob die Zusammenhänge, die einem bei all der statistischen Auswertung unterkommen, wirklich begründet oder vielleicht eher Zufall sind. Es kann also durchaus zu Fehlschlüssen kommen, die Zusammenhänge sehen, wo gar keine sind. Das nennt man einen „cum hoc ergo propter hoc“-Effekt – „mit diesem, folglich wegen diesem“. Ein prominentes Beispiel für solche Scheinkorrelationen ist die Statistik, dass der Rückgang von Piraten die globale Erwärmung beeinflusst.
Wie man sich vor solchen Fehlschlüssen schützen kann und den tatsächlichen Einfluss von einzelnen Faktoren auf andere ermittelt, ist ein großes Thema, das wir in einer der nächsten Folgen gesondert beleuchten werden.
Die Ergebnisse der oben durchgeführten Untersuchungen wurden anschließend mit denen bei zufälligem Raten verglichen:

Besonders hoch mögen die Zahlen auf den ersten Blick nicht erscheinen, aber man muss sich zwei Dinge bewusst machen: Vergleicht man die Vorhersagegenauigkeit von 63% bei Neurotizismus mit den vorherigen 38% Zufallstreffern ergibt sich eine Verbesserung um den Faktor 1,7 – und das ausschließlich unter Verwendung von Metadaten. Diese Daten liegen jedem Provider vor und werden vielleicht bald schon ganz offiziell im Rahmen der drohnenden Vorratsdatenspeicherung für einige Monate aufbewahrt. Und dass die Daten für viele Stellen von Bedeutung sind, zeigt uns ihre Erwähnung bei den Geheimdienst-Analysten allemal. Aber auch andere haben Interesse. Beispielsweise bei der Personalauswahl kann solch eine Analyse hilfreich sein, denn dem Bankangestellten hilft ein gewissenhaftes Verhalten mehr als gelegentliche neurotische Anflüge. Und auch gezieltes Marketing lässt sich leichter betreiben wenn man weiß, ob der Konsument in spe sich vorrangig nach Abenteuern oder häuslicher Sicherheit sehnt.
Das alte Problem mit den Metadaten
Die Mächtigkeit der immer wieder gern kleingeredeten Metadaten zu demonstrieren, genau das war eines der Anliegen der Wissenschaftler. De Montjoye, einer von ihnen, sagt dazu:
We see a lot of comments along the lines of ‘It’s only metadata. It’s not personal. And it only gets personal when a human looks into it. […] We wanted to show an example at a small scale of what you might be able to do.
Dieses Ziel verfolgen viele. Von einer anderen Gruppe des MIT Media Lab wurde das Tool Immersion vorgestellt, mit Hilfe dessen man sich aus den Metadaten seines GoogleMail-Accounts ein eindrucksvolles Bild des eigenen Sozialgefüge erstellen lassen kann. Und erst kürzlich veröffentlichte die Universität Stanford eine Reihe Ergebnisse, die zeigen, wie man von Metadaten mit einfachen Mitteln auf die dahinterstehenden Personen schließen kann und so sensible Informationen wie Kontakte zu Selbsthilfegruppen, speziellen Ärzten und ähnlichem ableiten kann. Und auch wir haben in der Vergangenheit unzählige Beispiele beschwört, was man mit Metadaten alles anstellen kann.
Mittlerweile durften ja auch unsere Politiker an einigen Stellen erfahren, wie schmerzhaft es sein kann, zu wissen, wer mit wem wie lange kommuniziert. Zum Beispiel, als das W‑LAN des Europaparlaments gehackt wurde und plötzlich einige Parlamentarier Angst haben mussten, dass ihre etwas intensiveren Lobby-Beziehungen ans Licht kommen könnten. Also noch einmal: Beerdigt endlich die Vorratsdatenspeicherung! Und versucht nicht, aus der erwarteten Entscheidung des EuGH noch das letzte bisschen Datensammelwut herauszuholen, dass rechtlich irgend möglich ist.
Vielleicht hört ja irgendwann nochmal jemand auf uns.
In dieser Reihe erschienen:
- How-To Analyze Everyone – Teil I: Basics der Handyortung
- How-To Analyze Everyone – Teil II: Wie findest du eigentlich Zombiefilme?
- How-To Analyze Everyone – Teil III: Ich weiß, wo du heute abend sein wirst
- How-To Analyze Everyone – Teil IV: Kunden, die diese Feueraxt gekauft haben, mögen Zombiefilme
- How-To Analyze Everyone – Teil V: Der Algorithmus weiß besser als Du, wer zu Dir passt
- How-To Analyze Everyone – Teil VI: Neurotisch? Extrovertiert? Dein Provider könnte es wissen
- How-To Analyze Everyone – Teil VII: Zeig mir dein Gesicht
- How-To Analyze Everyone – Teil VIII: Browser-Fingerprints und Informationskrümel ohne Cookies
- How-To Analyze Everyone – Teil IX: Predictive Policing oder wenn Vorurteile Algorithmen füttern
- How-To Analyze Everyone – Teil X: Wie Computer herausfinden können, wer hier welche Texte schreibt