

Im heutigen Teil von How-To Analyze Everyone wird es ausnahmsweise nicht um einen bestimmten Algorithmus oder eine konkrete Technik gehen. Vielmehr wollen wir betrachten, wie Algorithmen bei der Polizeiarbeit eingesetzt werden und wie sie dazu führen können, dass sich Vorurteile selbst verstärken.
Menschen haben Vorurteile. Menschen arabischer Herkunft werden nicht selten mit islamischem Terrorismus assoziiert, Frauen interessieren sich mehr für Mode als für Technik und ein Fan von Dynamo Dresden ist automatisch gewaltbereiter Hooligan. Manche Vorurteile beruhen auf irrationalen Prägungen und Ängsten, andere generalisieren Vorkommnisse. Aber unabhängig davon schaffen sie im Kleinen wie im Großen gesellschaftliche Probleme und bauen Schranken auf. Eine ganz andere Dimension von Problemen bringen Vorurteile mit, wenn sie institutionalisiert werden. Etwa durch „Racial Profiling“, das heißt, wenn bestimmte Personengruppen aufgrund ihres Aussehens und vermuteten Herkunft vermehrt Kontrollen und Verdächtigungen seitens der Polizei ausgesetzt werden. Solche Praktiken wurden übrigens 2012 sogar von einem Gericht gebilligt und als legitim eingestuft. Noch weiter geht die Problematik, wenn nicht mehr nur Menschen bei der Verbrechensbekämpfung auf Basis von Vorurteilen agieren, sondern Computer diese umsetzen und manifestieren. Predictive Policing heißt die Technik, von der sich Polizeibehörden versprechen, Verbrechen erkennen und verhindern zu können, bevor sie entstehen. Dazu gehören eine Menge Daten, statistische Auswertungen und Profiling-Algorithmen. Das Ergebnis sind im Grunde genommen in Formeln und Code gegossene Vorurteile. Und so kommt es, dass zwischen Predictive Policing, Racial Profiling und anderen Diskriminierungen oft nur ein schmaler Grat liegt.
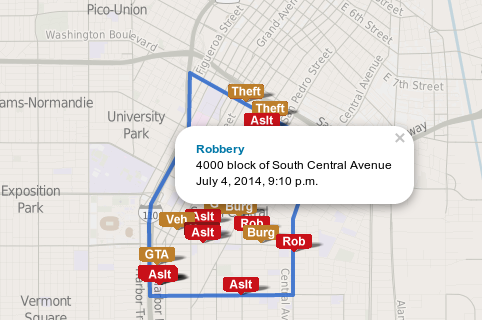
Die Anfänge: Landkarten und Statistiken
Einer der Vorläufer des modernen Predictive Policing ist CompStat, kurz für „Computer/Comparative Statistics“. Der dahinterliegende Arbeitsprozess wurde 1994 beim New York Police Departments eingeführt und basiert darauf, Verbrechensvorkommen auf einer Landkarte darzustellen und durch wöchentliche Absprachen Problembezirke zu identifizieren und etwa durch verstärkten Einsatz von Polizeistreifen in den Griff zu bekommen. Mittlerweile wird das System von vielen Polizeistellen in den USA und Kanada genutzt, Daten werden außerdem zur öffentlichen Nutzung zur Verfügung gestellt, woraus viele Crime Mapping Projekte entstanden, wie die L.A. Crime Map der Los Angeles Times oder CrimeReports. Aussagen, wie effektiv CompStat ist, sind schwer zu treffen. Zunächst scheinen die Zahlen beeindrucken: Gab es 1993 noch 1927 Morde, betrug die Zahl 1998 nur noch 629. Das bedeutet einen Rückgang um über 70%. Diesen allein CompStat zuzuschreiben wäre jedoch kurzsichtig, denn im selben Zeitraum wurden weitere Maßnahmen zur Verbesserung der Polizeiarbeit durchgeführt wie eine gründlichere Ausbildung von Polizeikommissaren.
Wenn Einzelne im Fokus der Algorithmen stehen, wird es intransparent
Eine Landkarte, die Verbrechensvorkommen illustriert, stellt ein unbestreitbar unterstützendes Arbeitsinstrument für die Polizei dar. Kombiniert mit fortgeschritteneren statistischen Verfahren, die zeitliche und räumliche Entwicklungen auswerten, lassen sich Trends erkennen, aber sie nehmen den Strafverfolgern keine Schlussfolgerungen ab. Das änderte sich, als man begann, die zur Verfügung stehenden Daten nicht nur anzuzeigen, sondern sie an Algorithmen zu verfüttern, um verdächtige Einzelpersonen herauszustellen. Die Algorithmen sollen Erkenntnisse generieren und Zusammenhänge erschließen, die auf den ersten Blick nicht sichtbar sind – ähnlich wie in einem Wetterbericht. 2009 hat das Department of Justice in den USA eine Ausschreibung veröffentlicht, in der nach neuen Methoden gesucht wurde, unter anderem:
Advanced analytical tools, including social network analysis tools and intelligent decision support systems for use in investigation to determine nonobvious relationships among suspects, victims, and others or to visualize criminal incidents and relationships.
Wie genau die Algorithmen aussehen, ist ein gut gehütetes Geheimnis, genauso wie auf welchen Daten die Erkenntnisse aufbauen, die aus ihnen entspringen sollen. Miles Wernick, Professor am Illinois Institute of Technology (IIT), der die Vorhersagen mit Wettervorhersagen oder medizinischer Diagnostik vergleicht, sagt:
It’s not just shooting somebody, or being shot. It has to do with the person’s relationships to other violent people.
Eine „Heat List“ mit den 400 wahrscheinlichsten Straftätern für Chicago, die auf ortsgebundenen Statistiken und Algorithmen des IIT beruht, traf Robert McDaniel. Der bekam im Sommer letzten Jahres Besuch der Polizei Chicago, die ihm zu verstehen gab, dass er unter Beobachtung stehe und lieber vorsichtig sein solle. Seine „kriminelle Karriere“ in Jugendtagen hatte aus Ordnungswidrigkeiten wegen Glücksspiel und Drogenbesitz bestanden, das begründet noch lange keine Einstufung als topverdächtiger zukünftiger Straffälliger. Ausschlaggebend für seine überraschend prominente Platzierung in der Liste der Hochverdächtigen schien ein Freund gewesen zu sein, der im Jahr zuvor erschossen worden war. Ihm könnte das gleiche passieren, wenn er nicht aufpasse, so die Ansage der Polizistin, die mit McDaniel sprach.
Keiner weiß, wodurch genau man verdächtig wird
Das heißt: Wer die falschen Freunde hat, läuft Gefahr, selbst auf einer Liste von Verdächtigen zu landen. Das bedeutet nicht nur, dass man im schlimmsten Fall aus Angst, falsch verdächtigt zu werden sein eigenes Verhalten selbstzensorisch anpasst und sich möglichst unauffällig verhält, sondern auch noch seine Freunde danach aussucht, ob sie eventuell auffällig sein könnten. Und was ist mit denen, die sich sowieso auf einer Liste befinden, weil sie in der falschen Gegend wohnen oder gewohnt haben? Es ergibt sich noch ein anderes Problem: Genaugenommen kann man nicht einmal wissen, woran man sein Verhalten anpassen sollte, um unauffällig zu bleiben. Hängt es von den Immobilienpreisen in der Nachbarschaft ab, dem Einkommen oder den Produkten, die man letzte Woche im Internet gekauft hat? Und wenn man es wüsste, würden Personen mit ernsthaften kriminellen Absichten diese Auffälligkeiten bewusst vermeiden können. Eine vorprogrammierte Intransparenz entsteht.
Auch in Deutschland will man automatisierte Verbrechensvorhersage
Nicht nur in den USA übt man sich im Predictive Policing, auch in Deutschland gibt es Bestrebungen, Software zum Erstellen von Heat Maps und Lists einzusetzen und das BKA besucht schonmal Schnupperkurse bei IBM. Etwa für Software wie Blue Crush, die im Memphis eingesetzt wird. Erst kürzlich gab der Dieter Schürmann, Landeskriminaldirektor in Nordrhein-Westfalen, im Behördenspiegel zum Besten, es gehe darum …
…, Tatorte und Taten auf Basis moderner IT und vorhandener Datenquellen vorherzusehen und vor den Tätern am Tatort sein zu können. […] Stellen wir an einem Ort das gleichzeitige Aufkommen ausländischer LKW und die Verwendung ebenso ausländischer Telefonkarten fest, und das in regionalen Bereichen die sich für mobile Einbruchstäter aufgrund ihrer Lage, etwa in Grenznähe oder Nähe der Autobahn, besonders eignen, sollte man aufmerksam werden.
Selbsterfüllende Prophezeiung und Manifestation
Afroamerikaner und Hispanics machten 2008 58% der Insassen in US-amerikanischen Gefängnissen aus, jedoch nur etwa ein Viertel der Gesamtbevölkerung. Von 2001 an ist jeder sechste farbige Mann mindestens ein Mal inhaftiert worden. Das heißt, die Polizei hat eine a priori höhere Erfolgswahrscheinlichkeit, wenn sie Nicht-Weiße und andere von Algorithmen als auffällig Gestempelte unter Beobachtung stellt. Das heißt aber nicht nur, dass sie mehr farbige Verbrecher fängt, sondern impliziert auch, dass sie ihre Aufmerksamkeit und ihre Ressourcen gleichzeitig von der unverdächtigeren weißen Gruppe abziehen muss. Sie ist also auf einem Auge blind und es ist die natürliche Folge, dass man als vermeintlich Unauffälliger öfter beim Begehen einer Straftat unentdeckt bleibt – denn wer würde vermuten, dass ein weißer Mann im Anzug und mit Aktentasche im Supermarkt Zigaretten stiehlt? Eine Untersuchung des Marijuana Arrest Research Project kommt zu ähnlichen Ergebnissen:
In allen 25 größten Bezirken Kaliforniens werden Schwarze öfters wegen Marihuanakonsums inhaftiert als Weiße. Typischerweise doppelt, drei oder sogar vier Mal so häufig wie Weiße. […] Studien der US-Regierung kommen übereinstimmend zu dem Schluss, dass schwarze Jugendliche seltener Marihuana konsumieren als weiße Jugendliche.
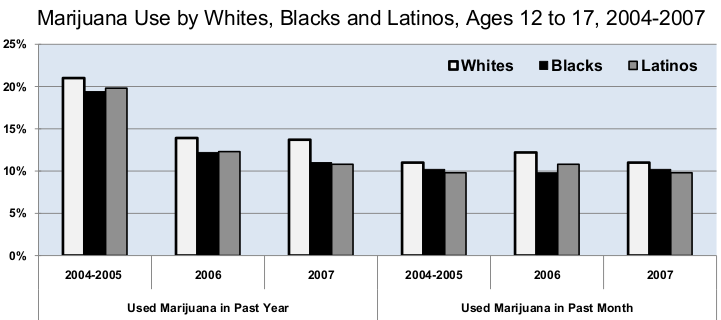
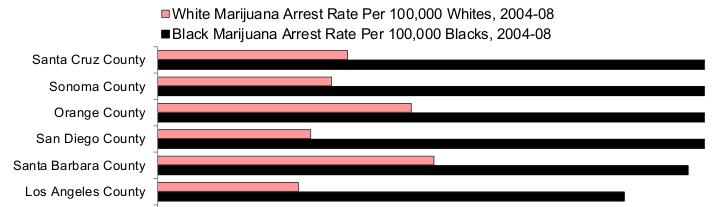
Die American Civil Liberties Union nennt das und die damit verbundene voreingenommene Datenbasis, auf der ein Algorithmus arbeitet, „Rückkopplungsschleife der Ungerechtigkeit“:
Wenn ein Algorithmus nur mit ungerechten Daten gespeist wird, wird er diese Ungerechtigkeit schlicht wiederholen, indem er der Polizei empfiehlt, mehr Polizeibeamte zur Patroullie in die „schwarzen Gegenden“ zu schicken. Dadurch erzeugt Predictive Policing eine Rückkopplungsschleife der Ungerechtigkeit.
Solche Verurteilungen stellen ein großes Problem für die zukünftigen Ausbildungs- und Arbeitschancen der Getroffenen dar – ein Umstand, der einer Selbstverstärkung tendenziöser Kriminalitätsraten weiteren Vorschub leistet.
Afroamerikanische Namen und verdächtige Werbeeinblendungen
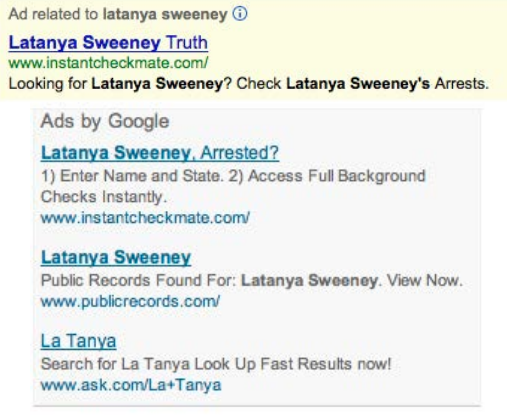
Nicht nur im Kontext von Strafverfolgung und Predictive Policing sind maschinelle Vorurteile zu beobachten. Im letzten Jahr stellte eine Studie der Harvard University fest, dass bei der Platzierung von Anzeigen durch Google ebenso Vorurteile zum Tragen kommen und gleichzeitig verstärkt werden. Annahmen darüber, welcher Herkunft der Nutzer vor dem Bildschirm ist, leitet Google anscheinend von Namen ab, die auf eine bestimmte Abstammung hindeuten. Besonders hervor tut sich der Anzeigenalgorithmus damit, dass er bei der Suche nach Namen, die vorrangig von Afroamerikanern getragen werden, vermehrt Werbung für Zuverlässigkeitsüberprüfungen einblendet – praktisch für den misstrauischen Arbeitgeber, der sicherlich nicht weniger misstrauisch wird, wenn er zusammen mit den Suchergebnissen des potentiellen neuen Angestellten Anzeigen mit Bezug auf Straftaten bekommt. Denn wir nehmen an: Wo Google Zusammenhänge findet, müssen ja auch welche sein.
Kurz gesagt: Vorurteile sind gefährlich
Aus all dem obigen kann man sehen: Algorithmen, die auf Vorurteilen basieren, neigen dazu, diese zu bestätigen und zu manifestieren. Es gibt massive Datenschutzprobleme, aufgrund proprietärer Verfahren und fehlender Transparenz lassen sich die Prozesse nicht nachvollziehen. Fehlurteile, die allen auf Wahrscheinlichkeit basierenden Algorithmen gegeben sind, lassen sich nicht wirksam korrigieren und können für den Einzelnen schweren Schaden anrichten. Und darum geht es: Predictive Policing – oder wie auch immer man die schönen Techniken nennen will – ist kein Wetterbericht. Sobald man es zum anlasslosen Ermitteln Verdächtiger nutzt, ist es die Zerstörung der Unschuldsvermutung ohne hinreichenden Anfangsverdacht und damit ein bedeutender Eingriff in die Menschenwürde.
In dieser Reihe erschienen:
- How-To Analyze Everyone – Teil I: Basics der Handyortung
- How-To Analyze Everyone – Teil II: Wie findest du eigentlich Zombiefilme?
- How-To Analyze Everyone – Teil III: Ich weiß, wo du heute abend sein wirst
- How-To Analyze Everyone – Teil IV: Kunden, die diese Feueraxt gekauft haben, mögen Zombiefilme
- How-To Analyze Everyone – Teil V: Der Algorithmus weiß besser als Du, wer zu Dir passt
- How-To Analyze Everyone – Teil VI: Neurotisch? Extrovertiert? Dein Provider könnte es wissen
- How-To Analyze Everyone – Teil VII: Zeig mir dein Gesicht
- How-To Analyze Everyone – Teil VIII: Browser-Fingerprints und Informationskrümel ohne Cookies
- How-To Analyze Everyone – Teil IX: Predictive Policing oder wenn Vorurteile Algorithmen füttern
- How-To Analyze Everyone – Teil X: Wie Computer herausfinden können, wer hier welche Texte schreibt