
Das US-amerikanische FBI plant Berichten der Electronic Frontier Foundation zufolge, bis zum nächsten Jahr eine Datenbank mit 52 Millionen Gesichtern zu erstellen, um Gesichtserkennung wirksam bei der Verbrechensbekämpfung anwenden zu können. Die Datenbank, auf die sich die Pläne beziehen, ist Teil des Projekts „Next Generation Identification“, das bereits seit mindestens 2009 besteht. Zur Datenbank gehören noch weitere biometrische Informationen wie Irisscans oder Fingerabdrücke, die Aufstockung des Bildmaterials würde jedoch einen entscheidenden Schritt vorwärts in der praktischen Anwendbarkeit bedeuten.
Bisher seien in der Datenbank 16 Millionen Bilder enthalten, wobei jedoch nicht eine Person einem Bild entspricht. Ausgehend von Zahlen aus dem Jahr 2012 kamen auf 13,6 Millionen Bilder etwa 6–7 Millionen Personen. Doch die Datenbank ist nicht nur aufgrund der schieren Masse an Bildern so bedenklich, es gibt noch weitere Faktoren, die sie zu einem ganz besonderen Überwachungsinstrument machen.
Viele frühere Datenbanken enthielten Informationen über ein einzelnes persönliches Identifikationsmerkmal. IAFIS (Integrated Automated Fingerprint Identification System) heißt beispielsweise eine bereits bestehende Fingerabdruckdatenbank des FBI. Andere Quellen enthalten Bilder, wiederum andere Kommunikationsdaten. NGI vereint all diese Informationen und fügt noch weitere hinzu.
Nicht nur Menschen, die sich in der Vergangenheit einer Straftat schuldig oder verdächtig gemacht haben, werden in die Datenbank integriert, sondern auch solche, die vormals nie auffällig waren. Es sollen 4,3 Millionen Bilder eingepflegt werden, die aus nicht-kriminalistischen Zusammenhängen entstanden sind. In der bisher bereits bestehenden Fingerabdruckdatenbank war eine Ergänzung um Fotos nur in Fällen Krimineller und mit besonderer Begründung möglich. Diese Einschränkung fällt weg und wird als Verbesserung angepriesen, außerdem entfällt eine Reduktion auf zehn Fotos pro Person und auf Gesichtsfotos, was eine Speicherung zusätzlicher Nahaufnahmen auffälliger Körperstellen wie Tattoos und Ähnlichem möglich macht.
Die Integration von Bildern muss nicht einmal an eine bestimmte Person gebunden sein. Es können auch einfach in Massen Aufnahmen von Überwachungskameras gespeichert werden, ohne dass zu dem bestimmten Zeitpunkt eine Personenzuordnung möglich ist. Zusätzlich sind die Zugriffsrechte ausgeweitet worden. Von Strafverfolgung bis Justizvollzug hat jeder Zugriff auf die Dokumente und das von lokaler bis auf internationale Ebene. Darüber hinaus werden die Suchmöglichkeiten aufgeweitet, beispielsweise durch textbasierte Eingaben oder biografische Kriterien.
Die Zuverlässigkeit der Ergebnisse ist dabei mehr als fragwürdig. Durch einen Fehler in der Erkennung könnte plötzlich ein völlig Unbeteiligter in den Ermittlungsfokus geraten. Womit wir beim Thema wären: Wie funktioniert eigentlich Gesichtserkennung?
Die Mutter aller Gesichtserkennungsverfahren, die 2001 veröffentlicht wurde, ist eine Arbeit von P. Viola und M. Jones aus dem Jahr 2001. In ihrem Paper „Rapid object detection using a boosted cascade of simple features“ legten sie einen Gesichtserkennungsalgorithmus mit Erkennungsraten von fast 94% bei einer Datenbank mit 507 unterschiedlichen Gesichtern vor. Und ihr Verfahren lieferte nicht nur brauchbare Ergebnisse, sondern die auch noch in kurzer Zeit, was damals eine Neuerung darstellte und bei den ständig wachsenden Datenmengen ein extrem wichtiger Faktor ist.
Das Prinzip der Erkennung besteht aus drei Phasen: Der Ermittlung von Features – bestimmten Bildeigenschaften – von Gesichts- und Nicht-Gesichtsbildern, dem Lernen eines Klassifikators und der kaskadierten Anwendung immer genauerer Klassifikatoren.
Featureermittlung
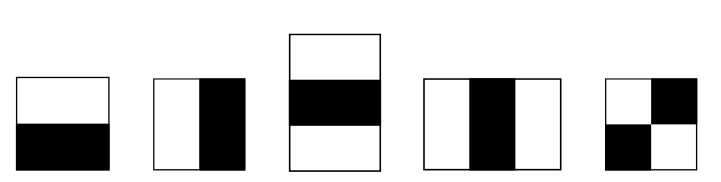
Die Grundlage zur Bestimmung der Bildeigenschaften, die für die Erkennung genutzt werden, ist beinahe schon lächerlich einfach. Es sind schwarz-weiße Blöcke:
 |
 |
 |
|---|---|---|
| ∑grün-∑rot=-0,37 | ∑grün-∑rot=-1,10 |
Der Wert bei Anwendung des größeren Filters hat einen wesentlich kleineren Betrag als der des 2x2-Filters. Daran sieht man, dass der durchschnittliche Helligkeitsunterschied im ausgewählten Bildausschnitt nicht sonderlich groß ist, aber im kleinen Ausschnitt eine kantenartige Struktur besteht. Somit sind große Filter logischerweise für grobe Helligkeitsverläufe gut, kleine für Kanten und andere Details.
Schaut man sich ein menschliches Gesicht an, kann man leicht sehen, dass typischerweise um die Augen ein starker waagerechter Helligkeitsübergang liegt, sowie ein senkrechter im Nasenbereich. Das wären schonmal zwei gute Anhaltspunkte. Gilt im Übrigen auch für Zombies, falls die betreffenden Gesichtsteile noch vorhanden sein sollten – nachdem beim letzten Mal der Mangel der ansonsten in dieser Reihe prominent vertretenen Untoten bemängelt wurde:
 |
 |
 |
Bild CC-BY-NC 2.0 via flickr/wvs
Viola und Jones haben mit Bildausschnitten einer Größe von 24x24 Pixeln gearbeitet, um ihrem System den Unterschied von Gesicht zu Nichtgesicht beizubringen. Das ergibt insgesamt ca. 160.000 verschiedene Summenwerte wenn man die Blöcke für jede mögliche Skalierung und jede mögliche Position anwendet. Mit so einer Menge lässt sich allerdings nicht besonders schnell und komfortabel arbeiten, außerdem sind nicht alle Werte gleich wichtig wie andere. Das erinnert an ein altes Problem aus Teil III. Die Lösung haben wir damals auch schon kennengelernt.
Klassifikator
In kurzer Wiederholung und Zusammenfassung: Man sucht sich die Features, die am meisten Bedeutung enthalten. Das geschieht, indem man zunächst einen „schlechten“ Klassifikator erstellt und nach und nach die Gewichtung einzelner Merkmale anpasst. So erhält man am Ende ein gutes Modell, dass aus den besten einzelnen, nicht so guten, aber dafür einfachen Faktoren zusammengesetzt ist.
Kaskadierte Erkennung
„Aus den besten einzelnen …“ – Zugegeben, das ist eine sehr vage Äußerung, aber diese Vagheit ist genau der Fakt, den das Verfahren ausnutzt, denn bei einer kleinen Anzahl Klassifikationsmerkmale ist die Erkennung zwar gröber, aber dafür auch schnell. Nimmt man jetzt den Fakt hinzu, dass ein Großteil an Bildern typischerweise aus Hintergrund und nicht aus Gesicht besteht, also negative Ergebnisse liefern wird, ahnt man worauf es hinausläuft: Man wendet zunächst einen schwachen Klassifikator an. Wenn der sagt, dass kein Gesicht im gewählten Ausschnitt ist, wird mit dem nächsten weiter gemacht. Fällt die Entscheidung jedoch positiv aus, wird der nächstgenauere Unterscheider gefragt. Das geht weiter, bis der Bildteil bis zum komplexesten und vermeintlich genauesten Modell durchgedrungen ist.

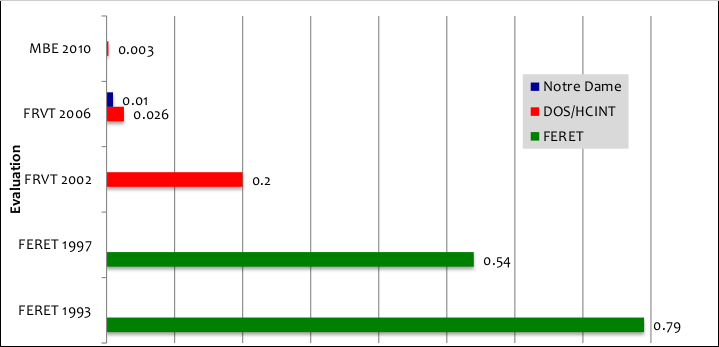
Mittlerweile sind die Erkennungsraten immens hoch. Die US-amerikanische Standardisierungsorganisation NIST führt regelmäßig Evaluationen für Gesichtserkennungssoftware von kommerziellen Anbietern und Universitäten durch. Der Prozentsatz nicht erkannter Gesichter bei einem vorausgesetzten Anteil fälschlicherweise akzeptierter Personen von höchstens 0,1 Prozent entwickelte sich von 79% im Jahr 1993 bis hin zu 0,3% beim letzten abgeschlossenen Test 2010.
„DeepFace“ arbeitet fast wie ein Mensch
Die neueste Entwicklung dazu kommt, wenig verwunderlich, aus dem Hause Facebook. Soll ein Mensch beurteilen, ob auf zwei beliebigen Bildern die gleiche Person abgebildet ist, erreicht man normalerweise eine Trefferquote von 97,53%, „DeepFace“, ein neues Verfahren, soll es bereits auf stolze 97,15% bringen und das auch unter widrigen Bedingungen. „DeepFace“ basiert auf „Deep Learning“-Techniken. Deep Learning ist ein bereits seit längerem bekanntes Prinzip im maschinellen Lernen, aber erst seit ein paar Jahren ist es wieder neu aufgelebt, als Google, Netflix und Facebook in den letzten Jahren angefangen haben, aktiv an den Verfahren zu forschen, die auf Deep Learning beruhen. Zum Neuerstarken des Forschungsfeld dürften die heute vorhandene Rechenleistung und die immensen Datenmengen geführt haben, die nun im Gegensatz zu früheren Zeiten zum Trainieren der Algorithmen zur Verfügung stehen und damit ermöglichen, ihre Stärken vollständig auszunutzen.
Deep Learning bildet in etwa die Funktionsweise unseres Gehirnes nach und basiert dabei wiederum auf künstlichen neuronalen Netzen – die uns im Übrigen sicherlich bald genauer über den Weg laufen werden. Durch die Simulation des menschlichen Verstehens werden so auch Zusammenhänge fassbar, die aus einer solchen Vielzahl von Faktoren zusammengesetzt sind, die explizit nicht mehr ausgedrückt und in Modellen formalisiert werden können. Bekannt wurde das am Beispiel des „Google Brain“, das 2012 dadurch bekannt wurde, dass es sich selbst beibrachte, Katzen mit einer Genauigkeit von beinahe 75% zu erkennen nachdem es mit 10 Millionen zufälliger Bilder aus Youtube-Videos gefüttert wurde und zwar ohne dass jemand dem System beigebracht hat, was eine Katze ist und was diese von einem Menschen oder anderen Objekten unterscheidet.
Facebooks DeepFace nutzte für seinen Lernvorgang vier Millionen Gesichtsbilder von 4000 Einzelpersonen aus der Facebook-Datenbank. Aber noch vor dem eigentlichen Lernvorgang wurden die Gesichter angepasst, um bessere Ergebnisse zu erzielen. Es gehört weithin zum Standard, die Helligkeit der Bilder untereinander zu mitteln oder sie auf den Gesichtsausschnitt zuzuschneiden, aber um perspektivische Verzerrungen auszugleichen, kann man wie im Anwendungsfall von DeepFace einen Schritt weiter gehen und ein 3‑D-Modell des Gesichtes erstellen, um damit eine Frontalansicht zu generieren.
Dafür muss man Referenzpunkte erkennen, zum Beispiel Augenwinkel, Irisposition und Kinn. Da man weiß und einem Algorithmus beibringen kann, wie Gesichter im Normalfall aufgebaut sind – einigermaßen symmetrisch, Augen auf gleicher Höhe, Nase in der Mitte, … – lässt sich anhand dieser Annahmen das Netz aus den gefundenen Punkten „gerade ziehen“ und die Perspektive hin zu einer Frontalansicht transformieren. Ein Versuch der manuellen Nachstellung:
 |
 |
Bild CC-BY-NC-SA 2.0 via flickr/shebalso
Aus den Frontalbildern werden insgesamt über 120 Millionen Parameter, die in mehreren Schichten ein neuronales Netz bilden. Das klingt furchtbar unperformant und kompliziert, aber viele der Parameter sind am Ende 0 und finden keine Berücksichtigung. Dadurch und durch diverse andere Optimierungen kann man erreichen, dass die Verarbeitungszeit trotz der vielen Faktoren letztlich minimal ist. In Messungen hat Facebook Zeiten von 0,3 Sekunden pro Bild erreicht, bei einer einfachen 2,2 GHz-CPU. Genau genommen ist DeepFace keine Gesichtserkennung, sondern ein Vergleich zweier Gesichter. Aber durch Adaption des Verfahrens kann dieser Zweck leicht erreicht werden.
Fazit
Bei einer ausreichend großen Datenbank zum Gesichtsabgleich ist es nur eine Frage der Zeit, bis es möglich ist, uns alle im Vorbeigehen zu identifizieren und unsere Bewegungen nachzuvollziehen. Nicht nur das FBI baut eine Riesendatenbank auf, auch in Europa gibt es Gegenstücke wie das Schengener Informationssystem. Das Vermeiden von digitalen Spuren in Form von Kommunikationsvorgängen, Kartenzahlen, W‑LAN-Anmeldungen und Co. wird uns dann kaum mehr weiterhelfen. Auch das Ausweichen vor Überwachungskameras, das sowieso schon beinahe unmöglich ist, wird nicht helfen, wenn winzige Helferlein wie Drohnen das Filmen im Verborgenen übernehmen.
So sarkastisch es klingt: Wenn schon nicht zu vermeiden sein wird, dass wir gefilmt werden, bleibt nur zu hoffen, dass die Verfahren zur Erkennung immer weiter perfektioniert werden, um die Prozentzahl falsch positiver Erkennungen zu reduzieren. Damit würde sich immerhin das Risiko minimieren, plötzlich auf einer Liste Verdächtiger zu landen, wenn man gar nicht am Ort eines Verbrechens oder konspirativen Versammlung zugegen war.
Die Vision ist düster, aber nicht besonders weit entfernt. Eine spontane, realistische Lösung vorzuschlagen fällt schwer. Oder habt ihr eine Idee parat?
In dieser Reihe erschienen:
- How-To Analyze Everyone – Teil I: Basics der Handyortung
- How-To Analyze Everyone – Teil II: Wie findest du eigentlich Zombiefilme?
- How-To Analyze Everyone – Teil III: Ich weiß, wo du heute abend sein wirst
- How-To Analyze Everyone – Teil IV: Kunden, die diese Feueraxt gekauft haben, mögen Zombiefilme
- How-To Analyze Everyone – Teil V: Der Algorithmus weiß besser als Du, wer zu Dir passt
- How-To Analyze Everyone – Teil VI: Neurotisch? Extrovertiert? Dein Provider könnte es wissen
- How-To Analyze Everyone – Teil VII: Zeig mir dein Gesicht
- How-To Analyze Everyone – Teil VIII: Browser-Fingerprints und Informationskrümel ohne Cookies
- How-To Analyze Everyone – Teil IX: Predictive Policing oder wenn Vorurteile Algorithmen füttern
- How-To Analyze Everyone – Teil X: Wie Computer herausfinden können, wer hier welche Texte schreibt