

Trinkt man aus einem Glas, hinterlässt man seine Fingerabdrücke. Kämmt man sich das Haar, bleiben eindeutige DNA-Spuren zurück. Schreibt man einen Text, hinterlässt man seinen stilistischen Fingerabdruck, heißt es oft. Doch die Frage ist: Kann man anhand des Geschriebenen ablesen, wer einen Text verfasst hat? Und reicht dazu ein einzelner Tweet oder muss es schon eine mehrseitige Abhandlung sein? Dem wollen wir in der heutigen Folge von „How-To Analyze Everyone“ nachgehen.
Die Disziplin, mit der wir es zu tun haben nennt sich Stilometrie – das „Messen“ von Stil mithilfe statistischer Methoden. Damit lassen sich eine ganze Reihe von Fragestellungen behandeln, eine Hauptanwendung ist die Autorenerkennung beziehungsweise ‑zuordnung. Weitere sind die Autorenverifikation, auch zum Nachweisen von Plagiaten, das Ermitteln von Autoreneigenschaften wie Alter und Geschlecht sowie die Ermittlung stilistischer Inkonsistenzen, etwa um bei gemeinsamen Werken Rückschlüsse auf die Autorschaft bestimmter Teile zu treffen.
Die Algorithmen, mit denen man Autorenerkennung angehen kann, sind zahlreich. Wie immer steht quasi die ganze Palette aus der künstlichen Intelligenz zur Verfügung und jeder Forscher hat seine Lieblingsverfahren (Stichwort: „Wer einen Hammer hat, …“). Wir wollen uns erstmal den groben Verfahrensweg vornehmen, bevor wir uns um die konkrete Erkennung kümmern. Praktischerweise versammeln wir auf netzpolitik.org eine Menge Autoren, die eine Menge Text produzieren, bieten ergo eine ideale Ausgangsbasis, um alles einmal am eigenen Leib durchzuspielen.
Zum Mitmachen
Forscher der Drexel University haben zwei Tools entwickelt, die dabei helfen sollen, sich vor Autorenidentifikation zu schützen. JStylo analysiert den individuellen Stil des Nutzers und Anonymouth baut auf den Ergebnissen auf und versucht als Gegenpart dem Nutzer Hinweise zu geben, wie er ihn verschleiern kann. Wir werden JStylo nutzen, um Texte von Markus, Andre und mir zu untersuchen. Das Tool dazu kann sich jeder selber runterladen und Schritt für Schritt mitmachen.
Schritt 1: Testdaten sammeln
Disclaimer: Im Vergleich zu einer realen Anwendung ist die Menge an Daten, die wir hier zum Testen nutzen, lächerlich winzig und die Ergebnisse daher auch nicht verallgemeinerbar. Das Prinzip aber bleibt gleich.
Grundlage aller Klassifizierungs- und Lernverfahren sind Daten, idealerweise viele Daten. Wir geben uns mit einer kleinen Beispielmenge zufrieden, nämlich mit je zehn Texten pro Autor zum Erlernen der Charakteristika und je zwei zum Testen. Die Texte sind von großen Wortzitaten bereinigt, denn sonst würden wir ja beispielsweise nicht den Stil von Andre lernen, sondern den von Regierungssprecher Seibert oder Kanzlerin Merkel. Und, um es mit deren Worten zu sagen: „das geht gar nicht“.
Damit ihr euch die Texte nicht selbst zusammenkopieren müsst, hier das Tarbällchen zum Download.
Öffnet man JStylo, muss man dem Programm sagen, welche Daten es für die Erkennung benutzen soll. Das könnt ihr entweder manuell tun, oder ihr wählt unter ‚Load problem set …’ die ‚problemset_desc.xml’-Datei aus dem .tar.gz-Archiv aus. Vorher müsst ihr in der Datei noch *customdir* durch das Verzeichnis ersetzen, in das ihr das Archiv entpackt habt.
Schritt 2: Features wählen
Features sind diejenigen Merkmale, die dazu genutzt werden sollen, Autoren zu unterscheiden. Dazu gehören Eigenschaften des gesamten Textes an sich – wir hatten ja schon einmal festgestellt, dass sich die durchschnittliche Länge unserer Texte teilweise stark unterscheidet -, als auch Auffälligkeiten bei der Wortwahl, Satzstellung, Interpunktion bis hin zu typischen, immer wieder auftauchenden Fehlern.
Wir wählen einfach das bereits vorgegebene Set ‚Write Prints (Limited) (German)’ aus. Das Writeprints-Featureset enthält unter anderem, wie viele Ziffern im Text vorhanden sind, wie oft Wörter mit bestimmter Länge vorkommen, welche Satzkonstruktionen häufig sind und wie häufig Zweier- und Dreierwortgruppen auftauchen. Bei einigen von uns laut Analyse besonders beliebt: ‚in Berlin’ oder auch ‚wir sind gespannt’.
Schritt 3: Algorithmus aussuchen
Im ‚Classifiers’-Tab von JStylo finden sich unzählige Klassifikationsverfahren, die zur Autorenbestimmung eingesetzt werden können. Wir wählen ‚MultilayerPerceptron’ und heben uns die Erklärung für später auf.
Schritt 4: Let the magic happen!
Im letzten Schritt drücken wir einfach mal auf das ‚Run Analysis’-Knöpfchen und schauen, was sich ergibt. Als Analysetyp soll unser Algorithmus die Trainingsdaten, also die je zehn Dokumente von Markus, Andre und mir, nehmen, ein Modell daraus bauen und am Ende die Zuordnung der Testdokumente schätzen. Und das klappt auch ganz gut, nach einigem Warten zeigt sich folgender Output:
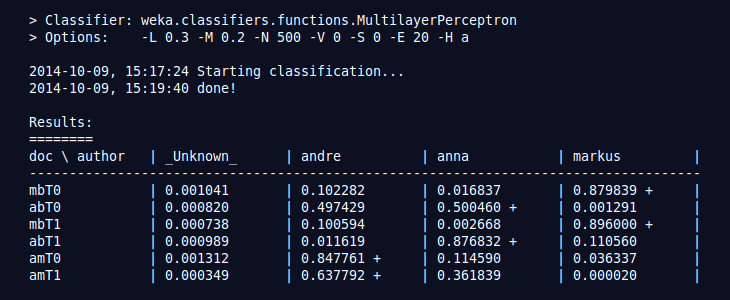
Das ‚+’ hinter dem Namen zeigt, wer als wahrscheinlichster Autor erkannt wurde, die Zahl weist darauf hin, wie eindeutig oder „sicher“ die Zuordnung ist. Die Testtexte ‚mbTx’ wurden korrekterweise Markus, die ‚amTx’-Beispiele Andre und der Rest mir zugeordnet.
Doch was passiert da im Hintergrund, was macht das „vielschichtige Perzeptron“ mit den Texten?
Multilayer-Perzeptron: Vorwärts füttern und rückwärts Fehler beseitigen
Ein Multilayer-Perzeptron ist eine Form eines künstlichen neuronalen Netzes. Ein einzelnes Perzeptron stellt dabei ein Modell einer realen Nervenzelle dar. Sie erhält Eingaben verschiedener anderer Zellen und anhand dieser Eingaben entscheidet sich, ob sie „aktiv“ ist oder nicht.
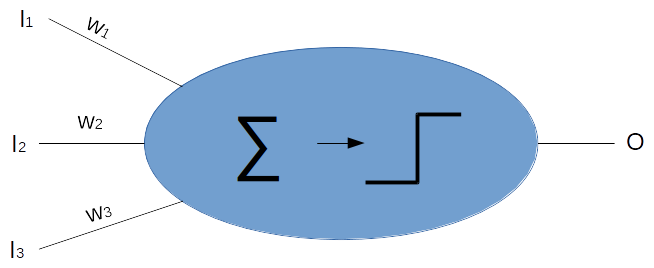
Formalisiert ausgedrückt: Die Eingaben I werden, multipliziert mit dem ihnen jeweils zugeordneten Gewicht w von der Aktivierungsfunktion Σ aufsummiert. Danach entscheidet eine Schwellwertfunktion, ob das Neuron aktiv ist, also ob die Ausgabe O den Wert ‚1’ oder ‚0’ hat. Dabei kann – muss aber nicht – auch mit einbezogen werden, welchen Aktivierungszustand das Neuron vorher hatte.
Genaugenommen ist ein einzelnes Neuron nichts anderes als eine Trennfunktion à la: „Wenn das Ergebnis größer als X ist, dann sei aktiv, sonst nicht“. Betrachten wir ein einfaches „Anna-Entscheidungs-Neuron“ mit einer binären Schwellwertfunktion: Das Neuron erhält als Eingabe, wie viele Wörter ein Text hat, wie oft ein Ausrufezeichen darin vorkommt, wie groß die durchschnittliche Wortlänge ist ebenso wie die Angabe der Häufigkeit der Wortgruppe „in Berlin“. Unser Neuron wurde bereits trainiert, das heißt, es kennt die Gewichtung der einzelnen Werte, die einen für mich typischen Text charakterisiert und den Schwellwert, ab dem es „feuern“ soll.
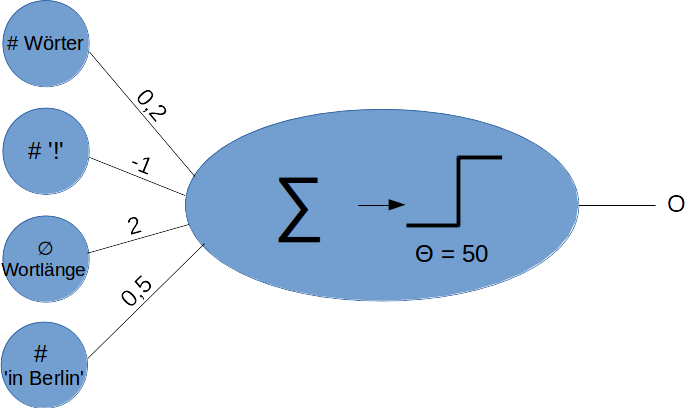
Setzen wir unserem Neuron jetzt einen Text von mir mit 213 Wörtern, 0 Ausrufezeichen, einer durchschnittlichen Wortlänge von 6,2 und dem einmaligen Vorkommen von „in Berlin“ vor. Die Aktivierungsfunktion Σ ergibt demnach:
Σ = 213 * 0,2 + 0 * ‑1 + 6,2 * 2 + 1 * 0,5 = 55,5
Da der Schwellwert Θ bei 50 liegt, ist unser „Anna-Entscheidungs-Neuron“ aktiv, also der Meinung, der analysierte Text sei von mir.
Ein so einfaches Modell reicht für die meisten realen Probleme nicht aus und man kann die Flexibilität eines Perzeptrons dadurch erhöhen, dass man mehrere Schichten einführt und Perzeptronen hintereinander schaltet, deren Ergebnisse sich auf die folgenden auswirken. Ein zweischichtiges Perzeptron zur Autorenerkennung könnte aussehen wie im folgenden Bild:
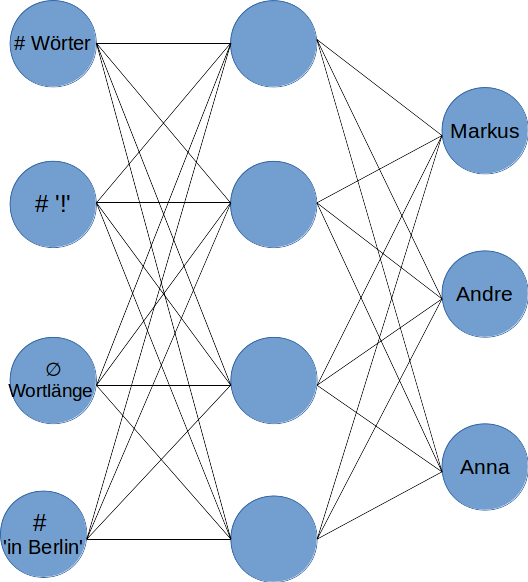
Die Input-Neuronen, die numerische Repräsentationen bestimmter Texteigenschaften repräsentieren, und die Outputneuronen, die entscheiden, ob ein Text zu einem Autor gehört oder nicht, bleiben erhalten. Es wird aber eine Schicht „versteckter“ Neuronen eingeführt, die eine größere Flexibilität bei der Formulierung von Bedingungen bietet. Was auffällt: Eine real-intuitive Bedeutung dieser verborgenen Schicht(en) ist nicht greifbar. Die Parameter, die für die einzelnen Gewichte und Aktivierungsfunktionen gesetzt werden müssen, können nicht einfach so geschätzt werden. Vor allem wenn man nicht nur von einigen wenigen wie hier, sondern von Modellen mit über hundert Neuronen ausgeht.
Das Training des Netzes muss daher automatisiert erfolgen. Dafür füttert man in drei sich wiederholenden Phasen das Netz mit Beispielen bekannter Autorschaft (Forward Pass) und schaut sich den Fehler an. Wenn er oberhalb einer festgelegten Akzeptanzschwelle liegt, modifiziert man von hinten nach vorn die Gewichte (Backward Pass) und beginnt von vorn.
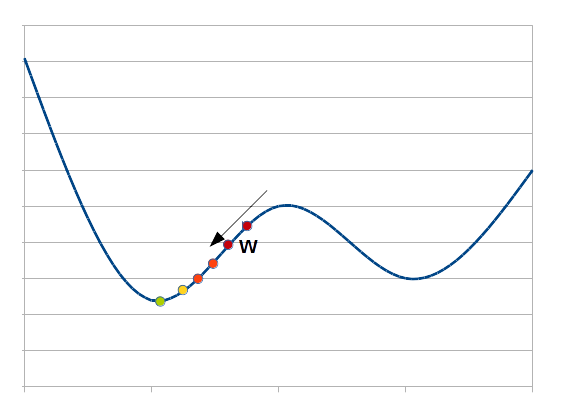
Die Modifikation der Gewichte erfolgt mit dem Gradienabstiegsverfahren. Ausgehend von anfänglich zufällig ausgewählten Gewichten wird ein Gradient ermittelt. Vereinfachend kann man sagen, dass die Steigung bestimmt wird, in welcher Richtung der Fehler größer und in welcher er kleiner wird.
Man kann sich leicht vorstellen, dass es dabei einige Fallstricke gibt. Werden die Anfangsgewichte ungünstig gewählt, kann es sein, dass man in einem lokalen Minimum endet und das globale Minimum viel kleiner ist – man landet im falschen Fehler-Tal. Wählt man eine zu große „Lernrate“, das heißt sind die Schritte in absteigende Gradientenrichtung zu groß, kann es passieren, dass enge, aber tiefe Täler übersprungen werden. Ist eine Fehlerkurve sehr flach, dauert das Verfahren sehr lange.
Herausforderungen
Wie immer stellt sich die reale Welt nicht so einfach dar, wie unser Spielzeugbeispiel. Alle Texte auf Deutsch, alle in ausreichender Länge, alle von der selben Gattung und in einem begrenzten Zeitraum verfasst – keine Standardbedingungen. Und dann auch noch manuell auf Zitate durchsucht. Im echten Leben steht man vor einer ganzen Reihe Probleme, die bewältigt werden wollen. Sehr kurze Texte lassen beispielsweise wenig Raum für individuelle Merkmale, wie beispielsweise auf Twitter oder in anderen Microblogs. Hinweise lassen sich durch teils inflationäre Nutzung von Satzzeichen à la ‚!!!!!?!!’ oder die Verwendung von Emoticons ziehen. Die Feststellung der Autorschaft wird ebenso über verschiedene Textgattungen oder sogar Sprachen hinweg erschwert. Ein Tagebucheintrag ist in einem anderen Stil verfasst als ein wissenschaftlicher Artikel oder gar Quellcode von Software. Und letztlich ist der sprachliche Ausdruck keine Konstante wie ein tatsächlicher Fingerabdruck, sondern entwickelt sich im Lauf des Lebens weiter.
Wo ist das Problem?
Stilometrische Verfahren zur Autorenerkennung wurden bereits lange vor dem Aufkommen des Internets als Massenpublikationsmedium genutzt. Diskussionen um die Autorschaft von Shakespeares Dramen haben bereits im 17. Jahrhundert Menschen auf die Suche nach individuellen Merkmalen im geschriebenen Wort getrieben. Weitere Anwendungsfälle sind Bekennerschreiben und andere politische Texte, an deren Autorschaft Strafverfolger im Besonderen interessiert sind. Die forensische Linguistik versucht, einen sprachlichen Fingerabdruck von Tätern zu ermitteln, um ihn dann zu überführen oder zu verfolgen.
Die Fülle von Texten im Netz bietet eine gute Ausgangslage für solcherlei Anliegen. Man kann sich vorstellen, dass alle Autoren unserer Seite willkommene Zielpersonen für eine Sprachanalyse darstellen. Jede Menge Fließtext, die dazu verwendet werden kann, ihren oder seinen stilistischen Fingerabdruck zu erstellen. Vom leichtfertigen Schreiben eines Bekennertextes für eine Gruppe sollte man daher lieber absehen, wenn man häufig Text unter seinem Realnamen publiziert.
Autorenidentifikation ist gefährlich für Whistleblower, Hacker und andere, die Grund haben, ihre Identität nicht offenlegen zu wollen. Auch die Nutzung von Pseudonymen wird durch Korrelationen zwischen Veröffentlichungen erschwert. In einer Studie des Privacy, Security, und Automation Lab der Drexel University gelang es in „Untergrund“-Foren wie blackhatpalace.com oder L33tcrew.org 72% der Nutzer korrekt zuzuordnen und das obwohl die Aufgabe durch mehrsprachige Beiträge und die Nutzung von leetspeak erschwert wurde.
Aber am Ende gilt, dass nur Schätzungen und Ähnlichkeiten ermittelt werden können. Kennt man auffällige Stilmerkmale, kann man sie vermeiden. Will man seine Autorschaft verschleiern, kann man Ghostwriter einsetzen. Und über die Zeit verändern sich auch die persönlichen Charakteristiken. So eindeutig, wie Strafverfolger Autorenidentifikation also manchmal gern sehen würden, ist sie nicht. Vor allem nicht im Internet.
Die Wissenschaftler der Universität Drexel haben auch herausgefunden, dass ihre Verfahren am besten dann funktionieren, wenn der Kreis der Personen, unter denen der Autor sich mutmaßlich befindet, auf weniger als 50 Personen begrenzt ist und pro Person Beispieltexte von insgesamt zumindest 6500 Wörtern vorliegen. Diese Bedingungen gelten, wenn man einen Plagiatsverdacht oder ein geschlossenes Forum von Personen hat, aber nicht, wenn man den Urheber eines politisch motivierten Textes „im Internet“ sucht.
Also: Vermeintliche Analysen immer mit Vorsicht genießen, aber auch daran denken, dass Pseudonyme nicht helfen, wenn der Text doch arge Ähnlichkeit mit dem restlichen eigenen Schriftmaterial hat. Und bitte nicht vergessen, dass alle stilistische Verschleierung wertlos ist, wenn man die Urheberschaft zwar nicht am Text, sondern beispielsweise an der IP-Adresse eines veröffentlichten Postings oder einer Mail nachvollziehen kann.
Frohes Schreiben!
In dieser Reihe erschienen:
- How-To Analyze Everyone – Teil I: Basics der Handyortung
- How-To Analyze Everyone – Teil II: Wie findest du eigentlich Zombiefilme?
- How-To Analyze Everyone – Teil III: Ich weiß, wo du heute abend sein wirst
- How-To Analyze Everyone – Teil IV: Kunden, die diese Feueraxt gekauft haben, mögen Zombiefilme
- How-To Analyze Everyone – Teil V: Der Algorithmus weiß besser als Du, wer zu Dir passt
- How-To Analyze Everyone – Teil VI: Neurotisch? Extrovertiert? Dein Provider könnte es wissen
- How-To Analyze Everyone – Teil VII: Zeig mir dein Gesicht
- How-To Analyze Everyone – Teil VIII: Browser-Fingerprints und Informationskrümel ohne Cookies
- How-To Analyze Everyone – Teil IX: Predictive Policing oder wenn Vorurteile Algorithmen füttern
- How-To Analyze Everyone – Teil X: Wie Computer herausfinden können, wer hier welche Texte schreibt