

Du hast alle Cookies deaktiviert? Und das „Do Not Track“-Häkchen gesetzt? Nutzt einen Proxy? Und du denkst jetzt ist es ziemlich schwierig, dich im Internet zu tracken? Leider wiegst du dich da in falscher Sicherheit, denn nicht nur ein Cookie kann verraten, wer du bist. Auch die Eigenschaften, die dein Browser über sich und dein System verrät, können ein ziemlich einzigartiges Identifikationsmerkmal sein. Genauso wie ein selten vorkommender Name es entbehrlich macht, auch noch Adresse/Geburtsort/Geburtsdatum einer Person zu prüfen, um festzustellen, um wen es sich handelt, kann ein einzigartiger Browser-Fingerprint es leicht möglich machen, einen Nutzer zu tracken – ganz ohne Cookies, das Einfügen von IDs in URLs, HTML-Formulare oder andere klassische Tracking-Mechanismen.
Das ist für diejenigen praktisch,die uns gezielt mit personalisierter Werbung beglücken wollen, auch wenn wir offensichtlich bereits Verkehrungen getroffen haben, damit genau das nicht passiert. Denn natürlich ist es aus kommerzieller Sicht ärgerlich, dass mittlerweile viele Nutzer Cookies blocken oder zumindest regelmäßig löschen. Wie das in Werbe-Sprech aussieht, kann man sich auf den Seiten von Zanox anschauen, einem großen Marketing- und ECommerce-Dienstleister:
Mit „zanox TPV Fingerprint Tracking“ (TPV – True Post View) erweitern wir unsere marktführende Tracking-Technologie mit einer passiven Lösung für das Tracking von Display-Werbemitteln. Das „zanox TPV Fingerprint Tracking“ basiert nicht auf dem Einsatz von Cookies und bietet damit eine präzise und zuverlässige Alternative, wenn Cookies gelöscht, deaktiviert oder mittels entsprechender Browser-Einstellung blockiert werden. […] Das zanox Tracking-System ist so konzipiert und dimensioniert, dass es alle Aktionen in Echtzeit verarbeiten kann und jederzeit unterhalb der maximal möglichen Arbeitslast bleibt. Derzeit bedient die zanox Tracking-Architektur etwa 600 Millionen Ad-Impressions, 50 Millionen Klicks und mehr als zwei Millionen Kunden-Transaktionen pro Tag.
Gleichzeitig demonstriert uns eine kleinen Infografik schön das Ziel des Ganzen, nämlich wie unsere persönlichen Daten ganz einfach zu Geld werden:
Aber zuerst einmal wollen wir uns anschauen, wie so ein Browser-Fingerprint eigentlich aussieht und warum er uns so gut identifizieren kann.
Welchen Fingerabdruck hat mein Browser?
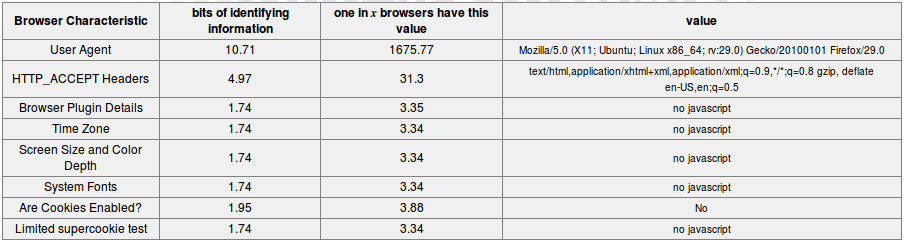
Einfache Wege sich anzuschauen, welche Charakteristika der eigene Browser dem Internet offenbart, bietet zum Beispiel die Electronic Frontier Foundation mit Panopticlick. Hat man nicht bereits Maßnahmen zur Minimierung der eigenen Verfolgbarkeit getroffen, bekommt man im Normalfall das recht ernüchternde Ergebnis, dass der eigene Browser unter den mehreren Millionen bislang getesteten einzigartig ist. Betriebssystem, installierte Schriftarten, Browserplugins und vieles mehr posaunen wir beim Surfen im Internet bereitwillig in die Welt hinaus. Zusätzlich dazu, was man preisgibt, zeigt Panopticlick außerdem an, wie verbretet die einzelnen Eigenschaften unter den Browsern sind, die bereits erfasst wurden. Oder anders ausgedrückt – wieviele Bits an Information man zur Identifikation bereitstellt. Je einzigartiger und detaillierter beispielsweise die „User Agent“-Angabe ist, die Angaben zu Browser, Betriebssystem und teilweise weiteren Infos wie Hardwareplattform bietet, desto mehr Informationsgehalt trägt diese Auskunft.

Ein ganz kurzer Ausflug in die Informationstheorie
„Bits of identifying information“ – klingt erstmal kryptisch. Was heißt das konkret: 12,56 bits, die durch den User Agent bereitstehen, um mich zu identifizieren? Das Maß des Informationsgehalts einer Angabe in Bit formalisiert, wie viel „Überraschung“ eine Nachricht enthält. Das heißt: Es zählt nicht die Menge an Information, sondern wieviel Neuigkeitswert diese bietet, wie wahrscheinlich ihr Auftreten ist. Mathematiker würden das so sagen:
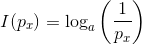
Bevor wir uns abschrecken lassen, betrachten wir ein einfaches Beispiel. Nehmen wir den Fall an, es gäbe nur Männer und Frauen auf der Welt und davon jeweils genau 50%, also ist die Wahrscheinlichkeit p 0,5. Dabei sind die möglichen Zustände, die Auftreten können – a – genau 2. In die Formel eingesetzt:
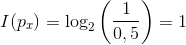
Die Information, dass eine Person weiblich ist, enthält also genau 1 bit Information. Logisch, denn es gibt zwei Zustände und definiert man männlich als „0“ und weiblich als „1“ hat man alles abgedeckt.
Gibt es mehr Auswahlmöglichkeiten, also mehr Unsicherheit, wie das Ergebnis aussieht, steigt auch der Informationsgehalt. Schauen wir uns das Beispiel des Browsers an. Die Wahrscheinlichkeit, dass ein anderer Browser den gleichen „User Agent“-String schickt ist laut Tabelle 1/6023,58, demnach in etwa 0,0166%. Der Informationsgehalt beträgt also, wenn wir als mögliche Zustände „hat diesen User Agent“ oder „hat einen anderen User Agent“ annehmen:
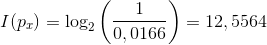
Damit lässt sich hoffentlich etwas besser verstehen, wie die Zahlen zustande kommen, die in der Auswertung angegeben sind.
Die EFF hat bei der Auswertung der Ergebnisse von Panopticlick übrigens festgestellt, dass Browser, die Flash und Java unterstützen, im Durchschnitt mindestens 18,8 bits Informationen bereitstellen, 94,2% dieser Browser waren in der Testmenge einzigartig. Henning Tillmann, der Browser-Fingerprints in seiner Diplomarbeit untersucht hat, kam außerdem zum Ergebnis, dass es bei 60 % der Nutzer über einen längeren Zeitraum zu keinerlei Veränderungen an ihrem Fingerprint kommt, bei 90% hatten sich höchstens drei Merkmale verändert.
Kommerzielle Tracking-Software kann noch mehr
Wer glaubt, die Informationen, die Panopticlick auswertet, wären schon genug, sollte sich bewusst machen, dass die Firmen, deren Tagesgeschäft das Tracking darstellt, sich noch weitaus mehr einfallen lassen, um Detailinformationen zu bekommen. Forscher der KU Leuven und der University of California haben drei kommerzielle Fingerprinting-Anbieter untersucht und konnten dabei einige Taktiken der „Cookieless Monsters“ rekonstruieren. Die Haupterkenntnis: Die professionellen Tracker schaffen es, noch weit mehr Informationen zu ermitteln. Dabei wurden vor allem Flash-Plugins genutzt. Die senden als Plattformangabe nicht „nur“ wie etwa Firefox das Betriebssystem mit Hardwarearchitektur, sondern noch dazu die genaue Kernelversion – was nicht nur beim Tracking hilft, sondern auch, wenn man gezielt Schwachstellen in bestimmten Systemversionen missbrauchen will. Ein weitere Lücke, die Flash in die die digitale Schutzmauer eines Nutzers reißen kann ist die Umgehung von IP-Adressen-Anonymisierung bei der Nutzung von HTTP-Proxies, da ein Flash-Plugin in der Lage ist, die Umleitung zu ignorieren und somit einem Tracker die wahre IP des Nutzers mitteilt.
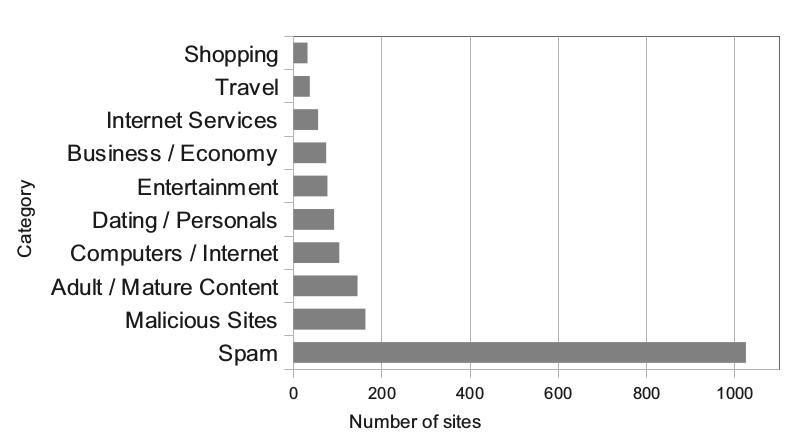 Interessant ist nicht nur, wie die Fingerprinting-Skripts arbeiten, sondern auch, wer sie nutzt. Die intuitive Vermutung fällt auf Shopping-Seiten, eine Statistik aus der obigen Studie kommt zu anderen Ergebnissen. Ganz weit vorn liegen Spam- und Schadseiten – womit man wieder bei genauen Infos zum Ausnutzen von Sicherheitslücken wäre.
Interessant ist nicht nur, wie die Fingerprinting-Skripts arbeiten, sondern auch, wer sie nutzt. Die intuitive Vermutung fällt auf Shopping-Seiten, eine Statistik aus der obigen Studie kommt zu anderen Ergebnissen. Ganz weit vorn liegen Spam- und Schadseiten – womit man wieder bei genauen Infos zum Ausnutzen von Sicherheitslücken wäre.
Doch wie immer gibt es nicht nur eine Seite der Medaille, sondern es ergeben sich auch vermeintlich nützliche Anwendungen, bei denen Browser-Fingerprinting eine Rolle spielt.
Patentierte Betrugserkennung über den Browser
 IBM hat ein System patentieren lassen, das die Möglichkeit bieten soll, Online-Betrug zu erkennen bevor er überhaupt entsteht. Dafür wurden Unmengen Verhaltensdaten vor dem Ausführen von Transaktionen wie Online-Bestellungen und Zahlvorgängen gesammelt. Die erfassten Informationen umspannen unter anderem das Navigationsverhalten des Nutzers – arbeitet er mit der Maus oder den Pfeiltasten, wohin klickt er am häufigsten -, den besagten Browser-Fingerprint und eine Statistik über gewöhnliche Anmeldezeiten und Orte des Nutzers. Alles plausibel, aber entsprechend der nebenstehenden Infografik von der IBM-Seite gehören auch Social-Media-Daten und „Big Data“ allgemein zu den Informationsquellen. Kurzum: Alles, was man bekommen kann, wird herangezogen, um das Normalverhalten des Nutzers zu modellieren. Weicht er vom über ihn bekannten Standard ab, tritt eine weitere Authentikationsstufe in Kraft bei der er beweisen muss, dass er wirklich die vorgegebene Person ist. Das können Captchas sein, aber auch andere Two-Factor-Authentication-Methoden wie SMS-Codes.
IBM hat ein System patentieren lassen, das die Möglichkeit bieten soll, Online-Betrug zu erkennen bevor er überhaupt entsteht. Dafür wurden Unmengen Verhaltensdaten vor dem Ausführen von Transaktionen wie Online-Bestellungen und Zahlvorgängen gesammelt. Die erfassten Informationen umspannen unter anderem das Navigationsverhalten des Nutzers – arbeitet er mit der Maus oder den Pfeiltasten, wohin klickt er am häufigsten -, den besagten Browser-Fingerprint und eine Statistik über gewöhnliche Anmeldezeiten und Orte des Nutzers. Alles plausibel, aber entsprechend der nebenstehenden Infografik von der IBM-Seite gehören auch Social-Media-Daten und „Big Data“ allgemein zu den Informationsquellen. Kurzum: Alles, was man bekommen kann, wird herangezogen, um das Normalverhalten des Nutzers zu modellieren. Weicht er vom über ihn bekannten Standard ab, tritt eine weitere Authentikationsstufe in Kraft bei der er beweisen muss, dass er wirklich die vorgegebene Person ist. Das können Captchas sein, aber auch andere Two-Factor-Authentication-Methoden wie SMS-Codes.
Neu ist die Idee nicht, ein früheres IBM-Patent stammt bereits aus dem Jahr 2007. Und ähnlich ist auch das Informieren und Blocken von Accounts bei „ungewöhnlichen“ Aktivitäten, das bereits jetzt von Google und Co. genutzt wird. Nur dass dann vielleicht schon der Zugang zum Mailpostfach geblockt wird, wenn die linke Hand statt der rechten zum Klicken benutzt wird, weil mit der anderen gerade eine Kaffeetasse gehalten wird oder man morgens um fünf ausnahmsweise spontan eine MP3 erwerben will, weil man gerade noch einen furchtbaren Ohrwurm hat, nachdem man vom Tanzen kommt. Und nicht, weil ein Anmelde-Versuch von einem bisher unbesuchten Ort stattfindet.
Was tun?
Klar ist: Das Missbrauchspotential von Browser-Fingerprints ist hoch und man sollte sich darum Gedanken machen, wie man sich bestmöglich schützen kann. Eine Patentlösung können wir nicht geben, aber ein paar Hinweise, wie man es den Trackern zumindest schwerer machen kann:
Sei Durchschnitt. Mit einem aktuellen Browser auf einem Mainstream-Betriebssystem kann man leichter in der Masse untergehen als das mit einem antiquierten Internet Explorer. Alternativ zum Browser und System könnte man auch den User Agent ändern. Der Browser sendet dann andere Informationen an die Webseite als eigentlich zutreffend. Geht zum Beispiel mit dem User Agent Switcher für Firefox, ist aber nicht zwingend sinnvoll. Denn wenn von einer einzelnen IP ständig andere User Agent Angaben gesendet werden, fällt das a) sowieso auf und b) landet man schnell automatisch als Spambot-Verdächtiger auf Blocklisten.
JavaScript und Flash deaktivieren. Vermeidet man die Nutzung von JavaScript und Flash, können keine Merkmale mehr aktiv vom Browser erfragt werden. Also keine Informationen mehr, welche Plugins genutzt werden, welche System-Schriftarten installiert sind u.v.m. Dafür gibt es unter anderem das beliebte NoScript, das auch Einzelentscheidungen ermöglicht, welche Seiten/Skripte geblockt werden und welche nicht. Wie stark sich das Ausschalten von JavaScript auf die Identifizierung auswirkt, kann man mit Panopticlick schön beobachten. In einer Testumgebung sank die indentifizierende Information von 20,44 bits auf 14,4 bits.
Vorher:

Nachher:
Nutze Tor. Tor anonymisiert nicht nur deine IP-Adresse, sondern der Tor-Browser schickt auch eine einheitliche User-Agent-Angabe mit blockt standardmäßig Java- und Flashanwendungen.
Nachdenken. Auch wer alle technischen Maßnahmen ergreift muss sich trotzdem noch bewusst machen, dass er auch durch unachtsames Verhalten schnell Datenspuren hinterlassen kann. Wer sich über Tor bei einem Mailanbieter mit Klarnamen anmeldet ist diesem gegenüber genauso wenig anonym wie mit einer direkten Verbindung…
 Fazit: Es ist kompliziert. Nicht nur der einzelne Nutzer sorgt sich um Browser-Fingerprints, auch im W3C beschäftigt man sich damit, wie man vermeiden kann, dass solches Fingerprinting erst möglich wird. Eine Präsentation vom Technical Plenary / Advisory Committee Meeting des W3C 2012 mit dem Titel „Is preventing browser fingerprinting a lost cause?“ zeigt deutlich, wo das Problem liegt:
Fazit: Es ist kompliziert. Nicht nur der einzelne Nutzer sorgt sich um Browser-Fingerprints, auch im W3C beschäftigt man sich damit, wie man vermeiden kann, dass solches Fingerprinting erst möglich wird. Eine Präsentation vom Technical Plenary / Advisory Committee Meeting des W3C 2012 mit dem Titel „Is preventing browser fingerprinting a lost cause?“ zeigt deutlich, wo das Problem liegt:
Internetprotokolle wurden weitgehend entworfen ohne die potentielle Bedrohung der Privatsphäre von Nutzern im Blick zu haben. Dementsprechend nutzen sie eine Menge Daten, die vielleicht vermieden werden könnten und so mehr Möglichkeiten zum anonymen Internetnutzung lassen würden. Und es ist wie immer schwer, nachträglich Maßnahmen zum Schutz selbiger im Nachhinein einzubauen. Notwendig wären also neue Protokolle, die Fingerprinting vermeiden. Womit wir auch beim generellen Vermeiden von Metadaten wären.
Ohne Browser-Fingerprints alles gut?
Sind wir endlich anonym, wenn wir es geschafft haben, alle Cookies zu blocken, verräterische Flash-Applikationen zu umgehen, JavaScript auszuschalten und noch jemand Protokolle entwirft, die unsere Browser-Fingerprints gar nicht erst aufnehmen und zum Beispiel keine User-Agent-Infos mehr in die Welt senden? Nein, natürlich nicht. Denn es wird wohl immer etwas zum Identifizieren geben. Zum Beispiel das Verhalten des Browsers und den Charakteristiken der Grafikkarte beim Rendern von Pixeln auf einem HTML5-Canvas-Element. Und die nächste Sicherheitslücke ist bestimmt nicht weit …
In dieser Reihe erschienen:
- How-To Analyze Everyone – Teil I: Basics der Handyortung
- How-To Analyze Everyone – Teil II: Wie findest du eigentlich Zombiefilme?
- How-To Analyze Everyone – Teil III: Ich weiß, wo du heute abend sein wirst
- How-To Analyze Everyone – Teil IV: Kunden, die diese Feueraxt gekauft haben, mögen Zombiefilme
- How-To Analyze Everyone – Teil V: Der Algorithmus weiß besser als Du, wer zu Dir passt
- How-To Analyze Everyone – Teil VI: Neurotisch? Extrovertiert? Dein Provider könnte es wissen
- How-To Analyze Everyone – Teil VII: Zeig mir dein Gesicht
- How-To Analyze Everyone – Teil VIII: Browser-Fingerprints und Informationskrümel ohne Cookies
- How-To Analyze Everyone – Teil IX: Predictive Policing oder wenn Vorurteile Algorithmen füttern
- How-To Analyze Everyone – Teil X: Wie Computer herausfinden können, wer hier welche Texte schreibt