
Willkommen zum vierten Teil von How-To Analyze Everyone – der Erklärserie zu den Verfahren, die unser Verhalten und unsere Persönlichkeit analysieren sollen. Wir bleiben heute im Zombiefilm-Genre, das schon im zweiten Teil dieser Serie als Beispiel herhalten musste. Diesmal soll es aber nicht darum gehen, anhand einer Bewertung herauszufinden, ob uns ein Film gefallen hat, sondern darum, im Voraus zu bestimmen, ob uns ein Film gefallen könnte. Solche Empfehlungssysteme begegnen uns ständig und jeder kennt sie von Online-Shops – das prominenteste Beispiel in diesem Bereich ist sicherlich Amazon mit seinen Vorschlägen aus den Kategorien „Wird oft zusammen gekauft“, „Welche anderen Artikel kaufen Kunden, nachdem sie diesen Artikel angesehen haben?“, „Kunden, die diesen Artikel gekauft haben, kauften auch“ und „Ihnen gefällt bestimmt auch…“
 Wie machen die das? Klar, Statistiken über Verkäufe gibt es, aber welche Techniken kann man nutzen, um zu ermitteln, wie wahrscheinlich es ist, dass wir uns für spezifische Produkte interessieren?
Wie machen die das? Klar, Statistiken über Verkäufe gibt es, aber welche Techniken kann man nutzen, um zu ermitteln, wie wahrscheinlich es ist, dass wir uns für spezifische Produkte interessieren?
Bei Empfehlungs-Techniken gibt es dafür zwei verbreitete unterschiedliche Grundansätze: Content-Based Filtering und Collaborative Filtering.
Filtern nach Inhalt
Beim CBF wird zur Empfehlung – wie der Name nahelegt – die inhaltliche Ähnlichkeit von Objekten bewertet. Ein Objekt wird dadurch als Zusammensetzung verschiedener Eigenschaften beschrieben. Im Filmbereich könnte man sich folgende vorstellen: Genre, Erscheinungsjahr, Regisseur, Drehbuchautor, Darsteller, Dauer, Schlüsselwörter zur Beschreibung, Sprache, Land, Soundtrack…
Will man einem Nutzer einen Film empfehlen, kann man darauf zurückgreifen, welche Filme er bereits gekauft oder bewertet hat oder man geht – was auch ohne Anmeldung möglich ist – vom aktuell betrachteten Filmprofil aus. Praktisch sind da außerdem Tracking-Cookies, die unseren Weg durch das Netz verfolgen und sich so merken können, was wir uns den lieben langen Tag anschauen. Von diesen Informationen ausgehend wird nach Filmen mit den selben (exact match) oder ähnlichen (best match) Eigenschaften gesucht.
| Day of the Dead | Dawn of the Dead | Zombieland | Barbie als Rapunzel | |
|---|---|---|---|---|
| Jahr | 1985 | 1978 | 2009 | 2002 |
| Genre | Horror | Horror | Horror, Komödie | Familie, Animation |
| Regisseur | G. A. Romero | G. A. Romero | R. Fleischer | O. Hurley |
| Drehbuchautor | G. A. Romero | G. A. Romero | R. Reese, P. Wernick | E. Lesser, C. Ruby |
| Land | USA | USA, Italien | USA | USA |
Sieht man sich das obige Beispiel an stellt man fest: Wenn ich bereits „Day of the Dead“ besitze, ist es wahrscheinlicher, dass ich „Dawn of the Dead“ kaufen will als „Zombieland“. Wobei „Barbie als Rapunzel“ eindeutig auf der Verliererposition steht. So weit, so plausibel. Persönlicher wird die Auswertung, wenn der Nutzer in einem Profil angeben kann, welche Kriterien ihm am Wichtigsten sind und damit stärker in die Wertung eingehen.
Filtern nach Nutzerverhalten
Um beim Content Based Filtering zu ermitteln, wie ähnlich sich zwei Objekte sind, muss man voraussetzen können, dass man sinnvolle Eigenschaften aus diesen ableiten und vergleichen kann. Aber nicht alles lässt sich scharf in Kategorien einteilen und es besteht die Gefahr, dass man leicht in Produktblasen steckenbleibt. Es würden dann beispielsweise immer nur Filme auf der Basis von Filmen empfohlen. Und dass, obwohl ich doch eigentlich nicht nur gerne Zombiefilme schaue, sondern auch an einem Zombie-Apokalypse Survival Kit interessiert wäre. Wie findet man das heraus?
Es liegt nahe, einfach zu schauen, was andere Nutzer schon getan und gekauft haben. Diesen Vorgang nennt man Collaborative Filtering – die Nutzer arbeiten mit ihrem Verhalten dabei unfreiwillig zusammen und helfen mit, dass in Zukunft noch besser verkauft werden kann. Aufzulisten, was oftmals zusammen gekauft wird oder andere Kunden gekauft haben, die den betreffenden Artikel gekauft haben, sind sehr einfache Methoden. Es geht bei dem Ansatz darum, die Ähnlichkeit von Nutzern zu ermitteln und nicht die von Produkten. Schon im analogen Zeitalter gab es manuelles CF: Empfehlungen von Freunden und Bekannten.
Eine einfache Form des automatisierten CF ist das Memory-Based-Filtering, bei dem die n ähnlichsten Nutzer ermittelt werden. Das kann zum Beispiel über ihre Produktbewertungen passieren. Um die Ähnlichkeit von Nutzern zu bewerten braucht man jedoch eine Metrik, wie das Kosinus-Ähnlichkeitsmaß. Dabei fasst man Eigenschaften von Nutzern zu einem Vektor zusammen – dem regelmäßigen Leser mag eine gewisse Ähnlichkeit zu anderen bereits behandelten Verfahren auffallen – und berechnet den Kosinus des Winkels zwischen den Vektoren.
![]()
Kommt 0 heraus, stehen die Vektoren senkrecht und haben denkbar wenig gemeinsam, bei 1 sind sie komplett gleich gerichtet. -1 bedeutete eine komplette Entgegenrichtung. Vorstellbar ist, dazu Produkte zu betrachten, die von beiden Nutzern bewertet wurden.
|
Rechenbeispiel für mich und Andi: ||a|| = sqrt(5² + 4² + 5²) = 8,12 ||b|| = sqrt(2² + 4² + 1²) = 4,58 K-Ähnlichkeit(a,b) = (5 * 2 + 4 * 4 + 5 * 1) / (8,12 * 4,58) = 0,83 |
Es wurde festgestellt: Peter und Hans haben einen ähnlichen Geschmack wie ich. Und beide haben zusätzlich vor kurzem eine positive Bewertung für eine Feueraxt aufgegeben. Treffer! Ein erster Schritt in Richtung Zombie-Apokalypse Survival Kit für mich.
Das funktioniert ganz gut, hat nur einen Nachteil: Wenn die Nutzerbasis groß wird, steigt der Aufwand schnell an. Jeder muss mit jedem anderen abgeglichen werden. Wenn die Produktpalette größer wird, so wie bei Amazon, tritt zusätzlich der Effekt auf, dass nur noch selten Kunden aussagekräftige Übereinstimmungen haben. Bewerten ich und Peter den gleichen Film in einer anderen Verkaufsedition, haben wir zwar den gleichen Geschmack, aber doch nicht das exakt gleiche Produkt bewertet.
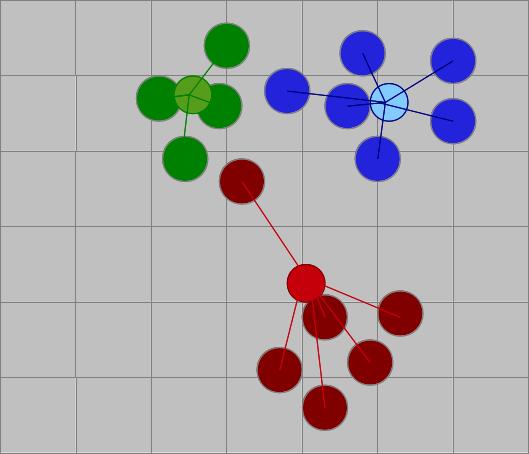
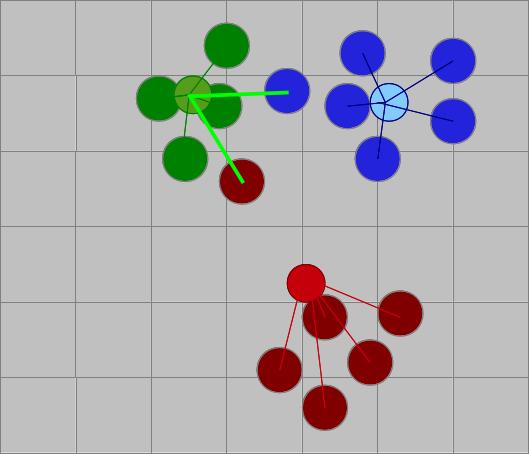
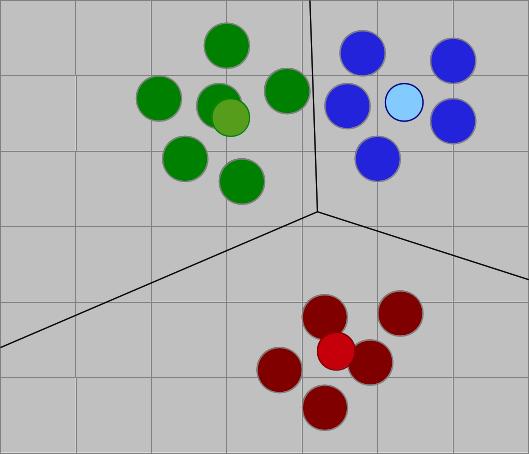
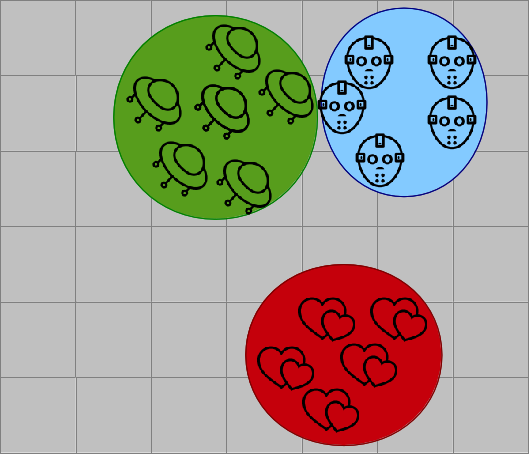 Performanter und skalierbarer sind modellbasierte Verfahren. Dabei betrachtet man nicht Nutzer-zu-Nutzer-Zusammenhänge, sondern ermittelt übergeordnete Eigenschaften, um ein Modell der Nutzer zu erstellen. Will man eine Empfehlung aussprechen, muss man nur nach beliebten Produkten in der zugehörigen Gruppe suchen. Eine Möglichkeit dafür ist die Clusterbildung. Dabei werden Nutzergruppen wie die durchschnittlichen Zombie-Fans zusammengefasst und ihre Eigenschaften berechnet.
Performanter und skalierbarer sind modellbasierte Verfahren. Dabei betrachtet man nicht Nutzer-zu-Nutzer-Zusammenhänge, sondern ermittelt übergeordnete Eigenschaften, um ein Modell der Nutzer zu erstellen. Will man eine Empfehlung aussprechen, muss man nur nach beliebten Produkten in der zugehörigen Gruppe suchen. Eine Möglichkeit dafür ist die Clusterbildung. Dabei werden Nutzergruppen wie die durchschnittlichen Zombie-Fans zusammengefasst und ihre Eigenschaften berechnet.
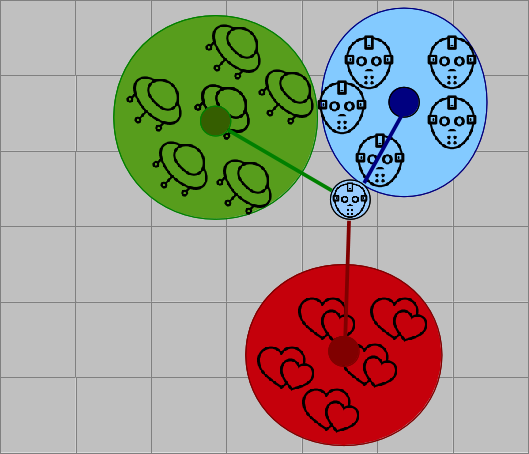 Will man meine Vorlieben schätzen, muss man mich nicht mehr mit allen Nutzern vergleichen, sondern nur noch mit dem prototypischen Science-Fiction-Nerd, dem generischen romantisch-veranlagten Teenagermädchen, etc. und erhält eine überschaubare Menge an Vergleichsgruppen. Interessant dabei ist, dass man die Gruppendefinition in der Regel vorher nicht kennen muss, sondern Cluster sich eigenständig bilden, zum Beispiel mit dem k-Means-Verfahren.
Will man meine Vorlieben schätzen, muss man mich nicht mehr mit allen Nutzern vergleichen, sondern nur noch mit dem prototypischen Science-Fiction-Nerd, dem generischen romantisch-veranlagten Teenagermädchen, etc. und erhält eine überschaubare Menge an Vergleichsgruppen. Interessant dabei ist, dass man die Gruppendefinition in der Regel vorher nicht kennen muss, sondern Cluster sich eigenständig bilden, zum Beispiel mit dem k-Means-Verfahren.
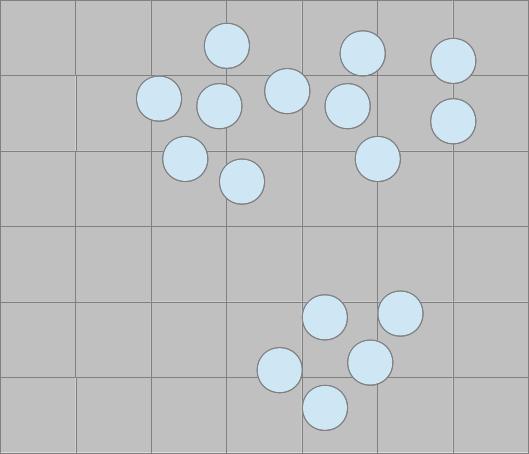
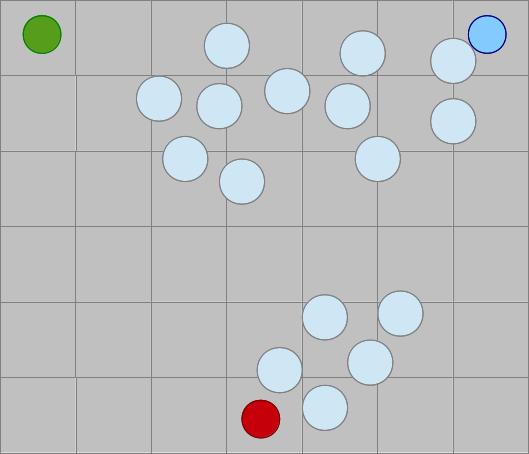
- Man hat eine Reihe ungeordneter Datenpunkte
- n zufällige Clusterzentren werden gewählt
- Den „Zentren“ werden die nächstgelegenen Punkte zugeordnet
- Die Zentren werden neu berechnet
- Schritte 3 und 4 werden solange wiederholt, bis sich nichts mehr an den Zentren ändert
 |
 |
 |
 |
 |
 |
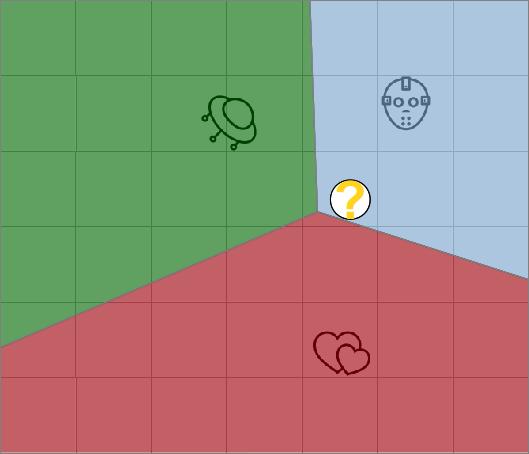
Unbekannte Datenpunkte (hier: mein Personenprofil) werden dann dem nächsten Clusterzentrum zugeordet. Erkenntnis: Ich bin potentiell dem Horror-Genre zugetan.
Neben Clusteringmethoden gibt es auch noch Ansätze mit Bayesschen Netzen, Neuronalen Netzen, Hauptkomponentenanalyse, …, aber da man diese Verfahren in allen möglichen anderen Kontexten aus dem Analyse-Bereich wiedertrifft, verschieben wir die genauere Betrachtung auf später.
Und so funktioniert Amazon?
Was genau hinter den Kulissen des Online-Versandhauses passiert, wird unter Verschluss gehalten. Die letzten ausführlicheren Informationen entstammen einem Beitrag aus dem Jahr 2003, man nimmt jedoch an, dass die Grundlagen des Systems gleich geblieben sind. Amazon greift auch auf Collaborative Filtering zurück, vergleicht aber nicht die Ähnlichkeit von Nutzern anhand der bewerteten Produkte, sondern die Ähnlichkeit von Produkten. Und zwar nicht, wie beim Content Based Filtering anhand konkreter Eigenschaften, sondern gemessen daran, wie oft Produkte gemeinsam im Warenkorb von Kunden landen.
Für jedes Produkt A im Warenbestand wird nachgeschaut, welche Kunden A gekauft haben. Dann geht man für jeden ermittelten Kunden durch dessen restliche Bestellungen und notiert, dass sowohl B,C,D,… von einem Kunden zusammen mit A gekauft wurden. Am Ende vergleicht man wieder die entstehenden Vektoren und kann die Produktähnlichkeiten bestimmen.
Am Beispiel: Wir ermitteln die Ähnlichkeiten verschiedener Produkte zu unserem vertrauten Zombie-Filmbeispiel und suchen alle Kunden, die Day of the Dead gekauft haben.
Kunden, die Day of the Dead gekauft haben, haben auch … gekauft
| Todd | Pete | Mark | John | Jake | gesamt | |
|---|---|---|---|---|---|---|
| Dawn of the Dead | 4 | |||||
| Zombie Survival Guide | 3 | |||||
| 5-Meter-Seil | 4 | |||||
| rosa Plastikpony | 1 | |||||
| Klopapier | 3 | |||||
| Feueraxt | 5 |
Einfach und effektiv fügt sich mit Seil, Klopapier und dem Survival Guide Teil für Teil meines Survival Kits zusammen…
Aber: Reines Collaborative Filtering hat zwei entscheidende Schwächen. Es kommt zu Problemen, wenn ein Produkt neu ist oder wenn ein Produkt nur von wenigen Nutzern gemeinsam gekauft wird, weil es sehr speziell ist. Für solche Fälle bietet es sich an, Content Based und Collaborative Filtering zu kombinieren, damit keine Empfehlungen verloren gehen.
Anwendungsfelder abseits von Amazon…
Empfehlungsplattformen gibt es für alles Mögliche: Filme, Musik, Autos, Handytarife, Pornos, Nachrichten, Webseiten, Veranstaltungen. Aber auch Soziale Netzwerke wie Twitter und Facebook empfehlen uns, wen wir kennen könnten oder wem wir vielleicht folgen sollten. Und auch Suchergebnisse, die durch Cookies und Profile personalisiert werden, sind Empfehlungssysteme.
Unsere gesamten Netzbewegungen werden daraufhin analysiert, was wir gut finden könnten, um uns die Nutzung von Diensten angenehmer zu machen, zum Beispiel indem man automatisch die wahrscheinlich präferierte Sprache einer Webseite anbietet. Vor allem aber aus Marketinggründen. Daraus erwächst sich ein Datenschutzproblem und die Gefahr der Filterblasenbildung.
Wenn man vermeiden will, dass andere uns das vorschlagen, was wir vermeintlich wollen, gibt es verschiedene Möglichkeiten, dagegen vorzugehen. Grundprinzip ist, so anonym wie möglich zu bleiben. Tracking-Cookies ablehnen, die eigene IP durch Tor, Proxies oder VPNs verschleiern, alternative Dienste ohne Anmeldungspflicht nutzen.
Oder ganz altmodisch im Konsumentenbereich: Den lokalen Einzelhandel unterstützen und den nächsten Film im Laden um die Ecke kaufen. Und am besten in bar bezahlen.
In dieser Reihe erschienen:
- How-To Analyze Everyone – Teil I: Basics der Handyortung
- How-To Analyze Everyone – Teil II: Wie findest du eigentlich Zombiefilme?
- How-To Analyze Everyone – Teil III: Ich weiß, wo du heute abend sein wirst
- How-To Analyze Everyone – Teil IV: Kunden, die diese Feueraxt gekauft haben, mögen Zombiefilme
- How-To Analyze Everyone – Teil V: Der Algorithmus weiß besser als Du, wer zu Dir passt
- How-To Analyze Everyone – Teil VI: Neurotisch? Extrovertiert? Dein Provider könnte es wissen
- How-To Analyze Everyone – Teil VII: Zeig mir dein Gesicht
- How-To Analyze Everyone – Teil VIII: Browser-Fingerprints und Informationskrümel ohne Cookies
- How-To Analyze Everyone – Teil IX: Predictive Policing oder wenn Vorurteile Algorithmen füttern
- How-To Analyze Everyone – Teil X: Wie Computer herausfinden können, wer hier welche Texte schreibt



Danke für die Mühe,
es wird Zeit, dass die Menschen verstehen, dass die Auswertung vollautomatisiert erfolgt und auch wie das passiert. Und das sie damit eben direkt Betroffene sind.
Viel zu oft musste ich in den letzten Monaten noch erklären, wie Metadaten-Analyse, Standort-Profil-Erstellung und ja eben auch Text basierte Analysesysteme funktionieren.
Das grauenhafte „um meine Emails zu lesen fehlt der NSA doch die Zeit“ verfolgt einen leider noch auf Schritt und Tritt.
Nochmals Danke.
Sieh es so: Jedes Mal wenn du es jemandem erklärst gibt es einen mehr, der es verstanden hat. Nicht aufgeben!
Sollte der cosinus nicht mal die Beträge sein, statt geteilt durch?
Schöne Reihe.
Für den sporadischen Leser wäre aber am Ende eines Artikels eine entsprechende Verlinkung zu dem oder den folgenden Artikeln eine feine Sache.
Hm, aber am Ende sind doch die drei Links zu den Vorgängern?
Hallo Anna!
Wirklich tolle Artikel machst Du da. Eine wahnsinnige Mühe steckst Du da rein. Und wenn man bedenkt, was Dich zu all dem gebracht hat … wäre es wunderbar, die Leute würden sich nicht alle nur am Arsch kratzen, sondern endlich verstehen wollen. … Der Funke für die Massen ist noch zu finden.
Danke Dir für deine Texte und Graphiken. Bin schon drauf und dran sie mir als PDFs für den Freundeskreis/Bekanntenkreis zu erstellen und zu verteilen. Blog lesen ist nicht jedermanns Ding, leider.
Auf jeden Fall: Weiter so. Wirklich toll.
Danke, das freut mich. Und wenn du das in die Offline-Welt trägst wäre das toll, auf die Idee bin ich noch gar nicht gekommen :)
Hi!
Gerne.
Öh, na wie will man die Leute sonst erreichen? Die, die das hier (Den Blog und seine Artikel) neu zu lesen beginnen sind ja schon mal einen Schritt weiter gekommen. Aber die ganzen Anderen, denen es sonst keiner erklärt oder es in schöne Bilder packt, die anschaulich sind und verständlich. Ganz salopp gesagt: Von Laien für Laien.
Hm, vielleicht mache ich es echt so: Schreibe klassisch per Post und flute ein paar gute Freunde von mir damit, einfach mal so. Mit dem Ärger könnte ich leben. ;-)
Gruß.
P.S.: Könntest Du es mir aus deinem Programm per PDF zukommen lassen? Dürfte mehr hermachen vom Layout. Aus dem Blog hier geht nur was verloren. Wenn nicht, könnte ich es auch in ein Text-Layoutprogramm packen. Wollte ich schon mal lernen. ;-)