
Bisher haben wir erfahren, dass die NSA auswertet, wo wir gerade sind und mit wem wir dort wahrscheinlich in Kontakt stehen. Aber die Forschung strebt nach höherem und möchte aufgrund unserer Bewegungen in der Vergangenheit am liebsten wissen, wo wir uns in Zukunft aufhalten werden. Gründe dafür gibt es viele. Die netteren darunter sind Möglichkeiten von Energieeinsparungen. Beispielsweise wenn ein Smartphone berechnen kann, ob es sich „lohnt“, sich bei einem anderen W‑Lan einzuwählen, wenn wir sowieso schnurstracks am Access Point vorbeilaufen. Weniger nette sind Marketingzwecke. Denn wenn mein Smartphone weiß, dass ich bald auf dem Weg ins Stadtzentrum sein werde, kann es mir noch schnell Werbung zu verschiedenen Sonderangeboten schicken.
Entwickelt man in der Forschung Algorithmen, die Daten auswerten und daraus Schlüsse ziehen sollen, ist immer ein großes Problem, geeignete realistische Datensätze zu finden. In Laborumgebung und mit Testdaten mag vieles optimal funktionieren, in der Realität sieht das meist schon ganz anders aus.
Daher kann man sich denken, wie wertvoll eine Datenbank voller realer Positionsdaten von 200 Einzelpersonen über einen Zeitraum von zwei Jahren hinweg ist. Eine solche erstellte Nokia in den Jahren 2009 bis 2011 in der Lausanne Data Collection Campaign. Gesammelt wurden nicht nur GPS-Position, die IDs der Funkzellen, bei denen das Telefon registriert war und eventuell bekannte WLAN-Access-Points, sondern auch Anruf- und SMS-Metadaten, Bluetooth-Informationen und Logs zur Nutzung von Anwendungen auf dem Mobiltelefon. Aus diesem umfassenden Datensatz entsprangen viele Publikationen zu Verhaltensstudien, sozialen Verbindungen und zur Positionsvorhersage.
Peters langweiliger Alltag
Will man einem Algorithmus beibringen, vorauszusagen, wo sich eine Person vermutlich als nächstes aufhalten wird, geht man in der Regel ähnlich vor, wie jeder Mensch das auch tun würde – man betrachtet die Verhaltensmuster und die vergangenen Aufenthaltsorte. Nehmen wir als Beispiel Peter. Peter arbeitet unter der Woche von 8 bis 17 Uhr in einem Büro in Berlin-Mitte, wohnt in Kreuzberg und trifft sich immer mittwochs abends zur Skatrunde in einer Kneipe im benachbarten Neukölln. Wenn mich nun montags um 18 Uhr jemand fragt, wo Peter sei, und ich behaupte ohne aktuelle Informationen, er sei zu Hause, habe ich gute Chancen, richtig zu liegen. So weit, so trivial. Für den Computer müssten dann bloß einfache Regeln aufgestellt werden:
((Mo ODER Di ODER Mi ODER Do ODER Fr) UND 8 bis 17 Uhr) → „Arbeit“
((Mo ODER Di ODER Do ODER Fr) UND NICHT 8 bis 17 Uhr) → „Zuhause“
(MI UND nach 17 Uhr) → „Skatrunde“
(MI UND vor 8 Uhr) → „Skatrunde“
nimmt man nun die Angabe Mo 18 Uhr, kann man leicht schlussfolgern:
((Mo ODER Di ODER Do ODER Fr) UND NICHT 8 bis 17 Uhr) → „Zuhause“
Abweichendes Verhalten
In der wirklichen Welt tendieren Menschen dazu, nicht ganz so regelmäßig zu funktionieren oder ihr Verhalten sogar plötzlich zu ändern. Idealerweise sollte ein Algorithmus flexibel genug und in der Lage sein, auch das zu berücksichtigen. Bringen wir etwas mehr Spannung in Peters Leben, denn die mittwöchentliche Skatrunde findet mittlerweile immer spontan an einem anderen Tag der Woche statt und auch Peter hat manchmal Hunger. Wenn er also nicht gerade zum Skat geht, schaut er in 10% der Arbeitstage noch kurz im Supermarkt vorbei. Es gibt also keine eindeutigen Vorhersagen mehr, sondern nur noch Wahrscheinlichkeiten. Damit lässt sich ein Modell von Peters Ortsübergängen erstellen (die Möglichkeit, dass Peter sich zwischen den zwei von uns gewählten Zeiträumen nicht bewegt, schließen wir der Übersichtlichkeit halber aus) :
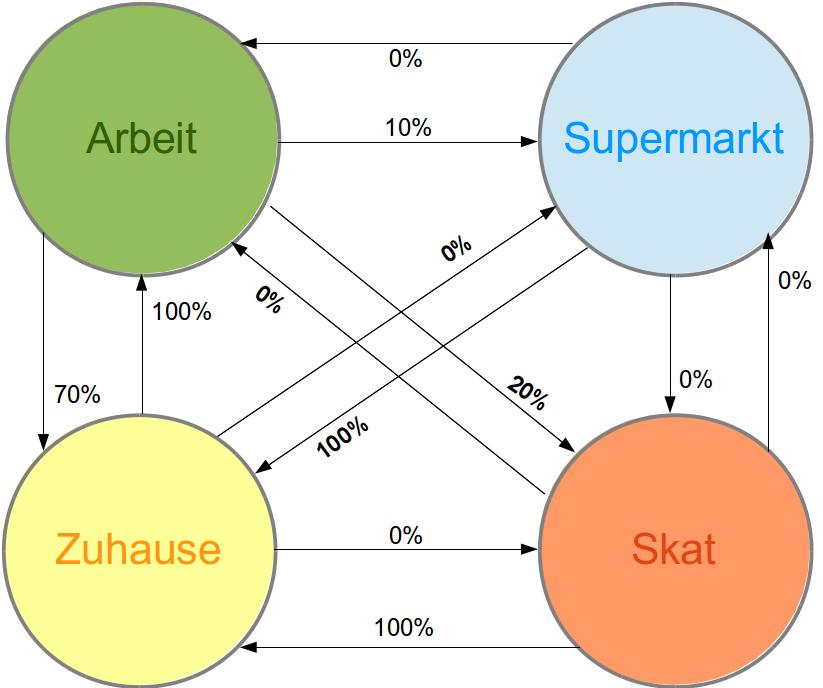
Man könnte jetzt also durch Multiplikation der Übergangswahrscheinlichkeiten die Wahrscheinlichkeit für die nächsten Bewegungsschritte von Peter berechnen. Zum Beispiel für die Folge
Arbeit – Supermarkt – Zuhause – Arbeit – Skat
ergibt sich die Wahrscheinlichkeit
0,1 x 1,0 x 1,0 x 0,2 = 0,02
also 2%. Diese Erkenntnis bringt uns jedoch nicht besonders viel weiter. Denn sie wird immer zu dem Ergebnis kommen, dass Peter mit größter Wahrscheinlichkeit abwechselnd zu Hause und auf der Arbeit ist. Außerdem müsste man jeden der Aufenthaltsorte Peters gesondert überwachen, um an diese Information zu kommen.
Was, wenn ich nicht jeden Ort überwachen kann?
Ignorieren wir kurz, dass das kein Problem für die NSA ist und gehen davon aus, dass derjenige, der gerne wissen möchte, wo Peter als nächstes ist, nur über eine Überwachungskamera an einer Kreuzung verfügt, also nie wirklich sieht, wo Peter gerade ist. An dieser Kreuzung kommt Peter praktischerweise auf jeden Fall vorbei und steigt dort entweder in die Bahn, den Bus bzw. radelt über die Straße. Auch wenn er beinahe immer die Bahn nimmt, wenn er zur Arbeit und zurück fährt, kann es passieren, dass er an einem schönen Tag Lust bekommt, das Rad zu nehmen. Die Beobachtungen lassen also, wie in der Realität, keine 100%ige Sicherheit zu, was dahinter steckt. Das Modell, das man aus den Beobachtungen aufbauen kann, nennt sich „Hidden Markov Model“, das „hidden“ deutet auf die quasi versteckten Zustände hin, die man nicht sehen kann, also wo sich Peter wahrscheinlich im Anschluss der Beobachtung aufhält. Man „trainiert“ das Modell, indem man ihm Beobachtungsfolgen und die zugehörigen resultierenden Zustände als Beispiele gibt, aus denen es dann die eigentlichen Übergangswahrscheinlichkeiten schätzt.
Und wo bleibt der Kontext?
Vielleicht ist aufgefallen, dass die oben stehenden Modelle, die mit Wahrscheinlichkeiten arbeiten, einen signifikanten Nachteil haben: Bisher wird noch kein Kontext einbezogen, sondern nur die durchschnittlichen Übergangswahrscheinlichkeiten. Man könnte aber realistischer schließen, wenn man berücksichtigen würde, welcher Wochentag gerade ist oder ob die Sonne scheint und damit die Wahrscheinlichkeit, Peter auf dem Fahrrad zu sehen, steigt. Eine Überwachungskamera könnte auch feststellen, ob Peter einen Anzug oder eine Jeans anhat – ebenfalls mögliche Hinweise darauf, wo er sich gerade hinbewegen könnte. Also gibt es nur entweder Kontextregeln ohne flexible Wahrscheinlichkeiten oder Wahrscheinlichkeiten ohne Kontext? Natürlich nicht.
In der letzten Folge wurde schon kurz die Support Vector Machine vorgestellt, bei der man Vektoren aus verschiedenen Eigenschaften zusammensetzt. Der Algorithmus lernt dann mit bekannten Beispielen, welche Vektoren zu welchen Klassen gehören. Für unbekannte Vektoren kann dann die wahrscheinlichste Kategorie geschätzt werden. Aber es gibt noch andere Verfahren. Eines davon nennt sich AdaBoost. Es hat den Vorteil, dass es lernen kann, welche Faktoren wie relevant bei der Schätzung von Ergebnissen sind. Bleiben wir bei Peter und mutmaßen einen bunten Blumenstrauß an Faktoren, die Einfluss darauf haben werden, wo Peter sich in einer Stunde aufhalten wird:
Uhrzeit, Wochentag, Sonnenschein, Temperatur, aktueller Aufenthaltsort, Dauer des aktuellen Aufenthalts, Uhrzeit, Kleidung, …
Klar wird schnell: Uhrzeit und Kleidung sind entscheidender dabei, ob Peter zur Arbeit geht als Sonnenschein und Temperatur. Denn einen Tag blau machen, um ins Schwimmbad zu gehen – so einen „Ausreißer“ erlaubt er sich nur selten. Treten solche Ereignisse in den Daten auf, mit denen wir versuchen, Peters Verhalten zu „lernen“, kann das aber zu Verwirrung führen. AdaBoost macht dabei folgendes: Es wählt zuerst (klassischerweise lineare) Unterscheidungskriterien, die nicht optimal sein könnten. Dann schaut man, welche Teile aus unseren bekannten Beispielen noch falsch erkannt werden und weist diesen eine höhere Bedeutung zu. Dann lernt man einen weiteren Unterscheider, unter der Berücksichtigung der Wichtigkeiten. So kann man aus vielen „schlechten“ Entscheidungsfunktionen, denen man unterschiedliches Gewicht beimisst, ein „gutes“ Modell zusammensetzen.
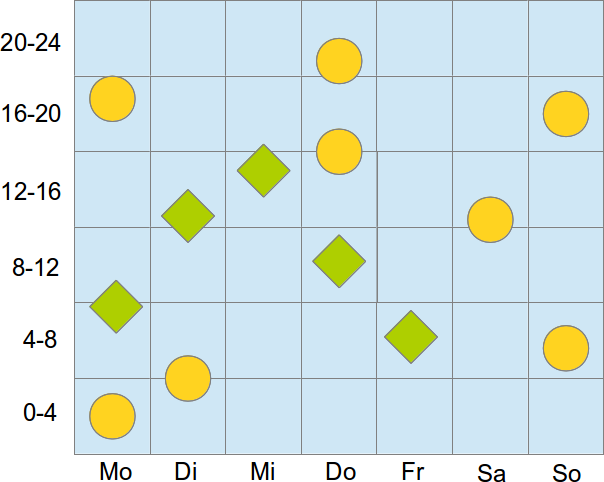 Ein einfaches Beispiel
Ein einfaches Beispiel
Wir wollen zwischen „Zuhause“ und „Arbeit“ unterscheiden und kennen Wochentag und Uhrzeit. Aus der letzten Woche haben wir einige Proben aus Peters Alltag genommen und stellen diese in einem 2D-Raum dar.
Jetzt beginnt man, die Kategorien voneinander abzutrennen und gewichtet die Klassifikatoren so, dass am Ende alle (oder ein gewünschter Prozentsatz) richtig erkannt werden.
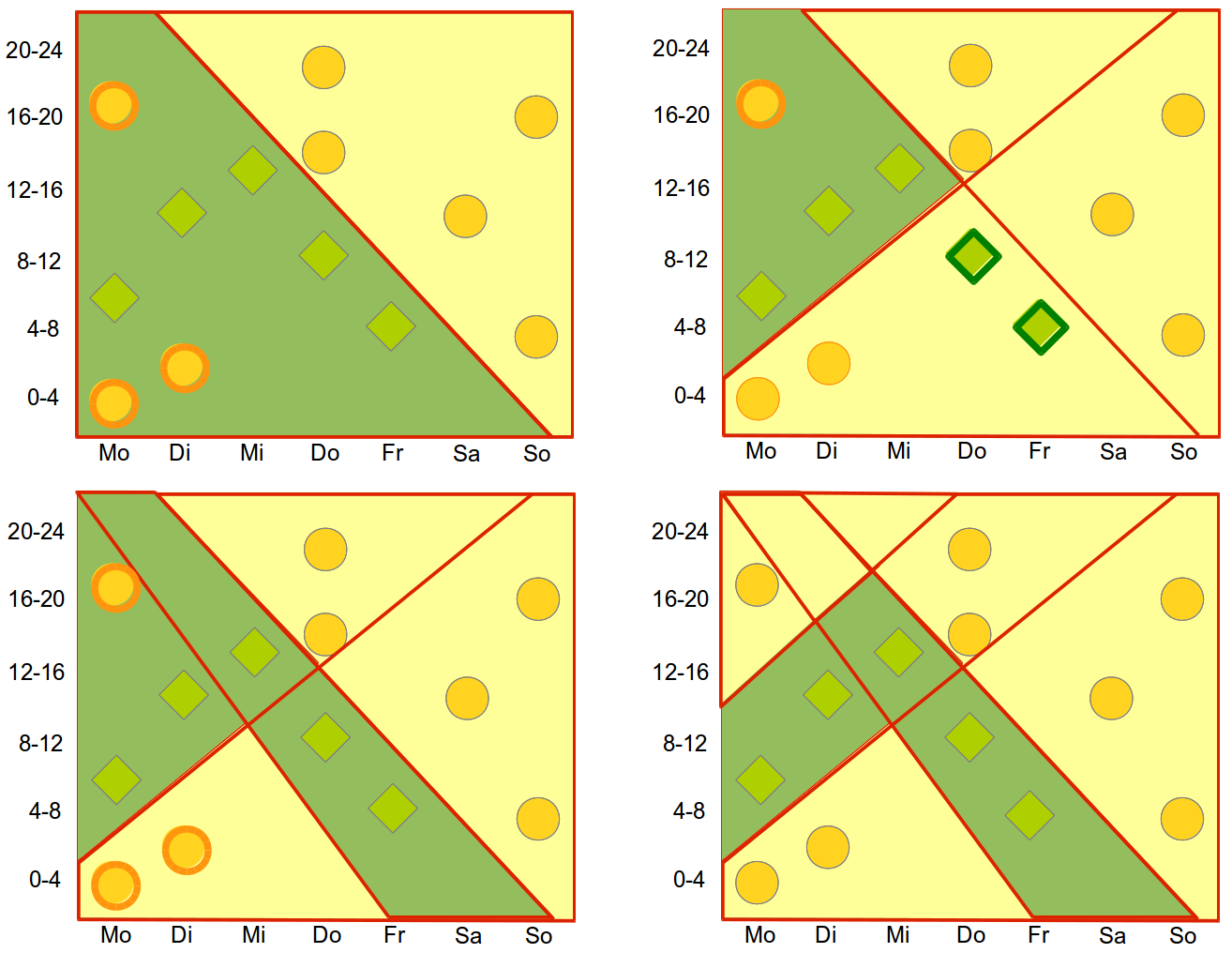
In dem Modell sind noch ersichtliche Fehler – Peter würde wahrscheinlich Samstag zwischen 0 und 4 Uhr nicht auf Arbeit sein – , aber durch eine genügende Anzahl an Lernbeispielen ließen auch die sich ausfiltern.
Wer interessiert sich dafür?
Dass sich Marketingfirmen dafür interessieren, wenn wir wahrscheinlich noch einen Abstecher in die Stadt machen werden, ist intuitiv ersichtlich. Was die NSA damit anfangen kann, nicht ganz so sehr. Aber es geht nicht nur um die isolierte Vorhersage oder Bestimmung unseres Aufenthaltsortes, sondern um die Möglichkeit, dass Algorithmen unser Verhalten auswerten und sogar vorhersehen können. Ob die NSA Ortsvorhersage-Maßnahmen benutzt oder selbst entwickelt, ist nicht bekannt. Aber es ist zumindest vorstellbar, dass sich durch solche Techniken elektronische Überwachungslücken schließen lassen, wo der Handyempfang nicht permanent ist und die Zielperson kein Smartphone dabei hat.
Was man bei alledem nicht vergessen darf: Kein Erkennungsverfahren wird in der realen Welt 100%ig korrekte Ergebnisse liefern. Gut für uns? Nicht ganz, wenn ein Computer zufällig ausspuckt, dass ich morgen mit einer Bombe vor der NSA-Hauptzentrale in Fort Meade stehen werde…
In dieser Reihe erschienen:
- How-To Analyze Everyone – Teil I: Basics der Handyortung
- How-To Analyze Everyone – Teil II: Wie findest du eigentlich Zombiefilme?
- How-To Analyze Everyone – Teil III: Ich weiß, wo du heute abend sein wirst
- How-To Analyze Everyone – Teil IV: Kunden, die diese Feueraxt gekauft haben, mögen Zombiefilme
- How-To Analyze Everyone – Teil V: Der Algorithmus weiß besser als Du, wer zu Dir passt
- How-To Analyze Everyone – Teil VI: Neurotisch? Extrovertiert? Dein Provider könnte es wissen
- How-To Analyze Everyone – Teil VII: Zeig mir dein Gesicht
- How-To Analyze Everyone – Teil VIII: Browser-Fingerprints und Informationskrümel ohne Cookies
- How-To Analyze Everyone – Teil IX: Predictive Policing oder wenn Vorurteile Algorithmen füttern
- How-To Analyze Everyone – Teil X: Wie Computer herausfinden können, wer hier welche Texte schreibt