
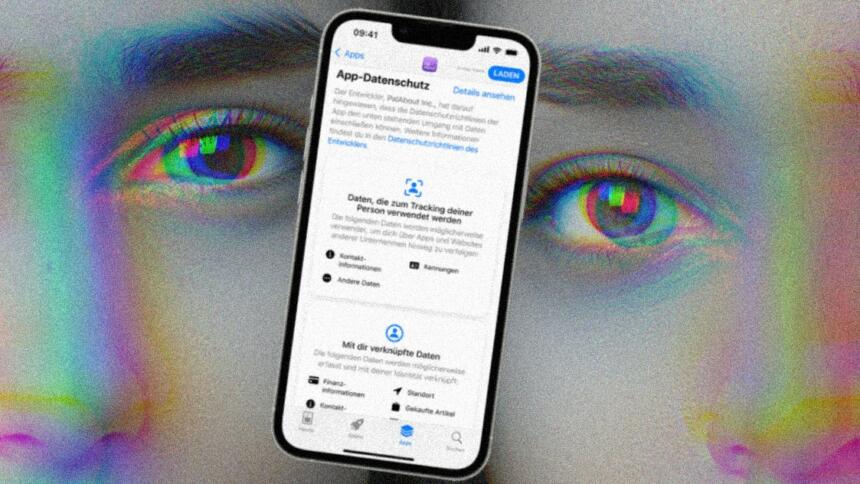
Eine klare Ansage schmückt viele Angebote in Apples App-Store: „Keine Daten erfasst“. Seit einem Jahr sind für Apps in Apples Betriebssystem iOS klare Datenschutzlabels verpflichtend. Sie sollen zeigen, ob und welche Daten die App an ihre Betreiber:innen oder Dritte weitergibt.
Viele Apps behaupten, keine Daten von Nutzer:innen zu sammeln. Doch zahlreiche Labels sind offenkundig falsch – das zeigt eine technische Auswertung, die netzpolitik.org exklusiv einsehen konnte. Der Informatiker Konrad Kollnig von der Universität Oxford hat 1,682 zufällig ausgewählte Apps aus Apples App-Store untersucht. 373 der getesteten Apps (22,2 Prozent) geben an, keine persönlichen Daten zu erfassen. Vier Fünftel davon, 299 Apps, kontaktierten jedoch sofort nach dem ersten App-Start und ohne jegliche Einwilligung bekannte Tracking-Domains. (Hier mehr Details über die Methode, eine Veröffentlichung der Daten soll bald folgen.)

Eine prominente App aus Kollnigs Datensatz: „RT News“ des russischen Staatssenders. Die App gibt an, keine Daten zu erfassen. Kollnig machte die Probe aufs Exempel, er lud sie auf sein Testgerät und steuerte ein paar beliebige Artikel an. Insgesamt schickte die RT-App an 19 Domains Daten weiter. Allerdings nicht nach Russland, sondern an Trackingdienste der US-Konzerne Facebook und Google, die Marktforschungsfirma ComScore und den Werbekonzern Taboola.
„Leider ist unklar, was mit Daten geschieht“
Eigentlich müsste eine solche Datensammlung im Datenschutzlabel angegeben werden, sagt Kollnig. Denn darin könnten sensible Informationen stecken, etwa über die Artikel, die sich Nutzer:innen in der App angesehen hätten. „Leider ist häufig unklar, welche Daten wirklich gesammelt werden und was mit diesen Daten geschieht.“
Besondere Vorsicht sei bei Apps geboten, die Zugriff auf den GPS-Standort haben, sagt der Informatiker. Wie Recherchen der New York Times gezeigt hätten, landen solche Standortdaten oft in den Händen von Datenfirmen, die sie zum Verkauf anbieten – ein klarer Fall von Missbrauch.

Wie viel an Tracking durch Apps passiert, untersuchen Kollnig, ein Doktorand am Informatikinstitut der Universität Oxford, und seine Kolleg*innen seit längerer Zeit. Zuletzt veröffentlichten sie eine Analyse von fast zwei Millionen Android-Apps im renommierten Journal Internet Policy Review. Ihre Ergebnisse sprechen Bände: Seit Wirksamkeit der Datenschutzgrundverordnung mit Mai 2018 habe sich wenig an der Lage verändert, rund 90 Prozent der Apps in Googles Play Store können demnach direkt nach dem Start Trackingdaten an Dritte schicken.
Für seine Analyse der iOS-Apps wählte Kollnig nach dem Zufallsprinzip Apps aus, die seit Januar 2020 in Apples Appstore zu finden sind und nachträglich ein Datenschutzlabel erhalten haben. Der Informatiker installierte die Apps automatisiert auf ein iPhone 8 mit dem aktuellen Betriebssystem iOS 15.2. Dort wurde jede App geöffnet, sonst fand aber keine Interaktion mit den Apps statt – auch keine Einwilligung zum Tracken. Anschließend untersuchte Kollnig den Datenverkehr zwischen dem Handy und dem Internet durch einen zwischengeschaltenen Rechner, einen sogenannten Man-in-the-middle-Proxy. Einige Apps installierte er zusätzlich zu Testzwecken manuell.
Apples Datenschutzlabels ernten Kritik
Grundsätzlich setzt Apple beim Datenschutz höhere Maßstäbe als andere Unternehmen, verkauft teilweise Produkte nach dem Konzept Privacy-by-Design. Doch Datenschutz und Privatsphäre sind auch Teil von Image und Marketing des Unternehmens, mit denen Konzernchef Tim Cook bei großen europäischen Datenschutzkonferenzen die Halle füllt.
Im Dezember 2020 führte Apple die Datenschutzlabels in seinem Store ein, „damit du besser verstehst, wie Apps deine Daten verarbeiten.“ Apple musste sich aber bereits seit Beginn Kritik an den Labels gefallen lassen. Mehr als ein dutzend falscher Behauptungen in App-Labels fand Washington-Post-Kolumnist Geoffrey A. Fowler im Januar 2021, darunter auch bei einer für Kinder gemachten Video-App und einem beliebten Spiel. Im Kleingedruckten der Labels sei zu lesen, dass Apple die Informationen der Anbieterfirmen gar nicht prüfe – die Angaben würden nur in vereinzelten Stichproben kontrolliert. Gleichlautende Vorwürfe erntet Apple auch später.
Ein Jahr später bleibt die Situation ähnlich: Kollnig fand in seiner Analyse zahlreiche beliebte Apps, die deutlich mehr Daten sammeln als behauptet. Etwa die Puzzle-App einer großen Spielefirma, die entgegen ihres Labels eine ID-Nummer von Nutzer:innen an zahlreiche Trackingdienste schickt. Oder die App des britische Met Office, des nationalen Wetterdienstes. Diese sendet heikle Informationen wie GPS-Daten an Google und Amazon und sammelt – ohne Ankündigung im Label – auch eine Nutzer:innen-ID.
Apple wollte zu der Analyse Kollnigs auf Anfrage von netzpolitik.org nicht konkret Stellung nehmen. Von dem Konzern hieß es lediglich, dass die Informationen in den Labels von den Entwickler:innen stammten, Apple aber vor allem die beliebtesten Apps im Rahmen seines Review-Prozesses auf die Richtigkeit der Angaben kontrolliere.
Oft wissen App-Betreiber:innen selbst nichts von Tracking
Dass so viele Daten aus beliebten Apps bei Dritten landen, hat aus Sicht des Informatikers Kollnig einen praktischen Grund. Trackingdienste würden üblicherweise über sogenannte Bibliotheken in Apps integriert. Bei Bibliotheken handelt es sich um fertige Unterprogramme, die bestimmte Aufgaben in einer App erledigen. Deren Nutzung erleichtert Programmierer:innen die Arbeit, bedeutet aber weniger Kontrolle über die fertige App. Denn viele Bibliotheken stammen von Konzernen wie Google, und in ihnen ist der Tracking-Code versteckt. „App-Betreiber haben häufig keine Möglichkeit den Programmcode dieser Bibliotheken nachzuvollziehen, da die Trackingunternehmen ihren Code üblicherweise nicht öffentlich machen“, sagt Kollnig.
Das Tracking bietet App-Anbieter:innen eine Möglichkeit, durch personalisierte Werbung Geld zu verdienen. „Der Wunsch von App-Betreibern nach finanziellen Einnahmen ist verständlich“, sagt der Jungwissenschaftler. Doch das Geschäft gehe zu Lasten der Nutzer:innen, die kaum über die gesammelten Daten Bescheid wüssten. Grund dafür seien auch die großen Tech-Konzerne, die es App-Betreiber:innen erschwerten, auf datenschutzfreundliche Alternativen zu setzen. Damit sich daran etwas ändere, müsste geltendes EU-Datenschutzrecht konsequent in die Praxis umgesetzt werden, sagt Kollnig.

>> Trackingdienste würden üblicherweise über sogenannte Bibliotheken in Apps integriert. … Deren Nutzung erleichtert Programmierer:innen die Arbeit, bedeutet aber weniger Kontrolle über die fertige App. Denn viele Bibliotheken stammen von Konzernen wie Google, und in ihnen ist der Tracking-Code versteckt. <<
Vielleicht sollte man mal damit anfangen, das Verhalten solcher libraries genauer zu untersuchen, und entsprechende Tabellen veröffentlichen.
Es ist relativ einfach, wenn die Library von Google, Facebook, Microsoft oder Apple kommt: Telefoniert nach Hause.
Und es gibt sehr komplizierte Methoden es ihr abzugewöhnenen – bis zum nächsten Update.
eingebundene Libraries zu untersuchen, ist eine Lebensaufgabe. Im Prinzip kann jede neue Version eine neue Schweinerei enthalten. Außerdem werden solche Libraries normalerweise nicht zu Fuß eingebunden, sondern über die jeweils benutzte Entwicklungsumgebung (IDE oder SDK). So kam vor knapp einem Jahr ans Licht, dass 2015 von Apples eigener IDE „Xcode“ eine manipulierte Version im Umlauf war. Die reicherte alle damit erstellten Apps mit einem Schädling namens „XcodeGhost“ an. Davon sollen 2500 Apps betroffen gewesen sein mit 130 bis 500 Millionen Nutzer:inne:n (die Zahlenangaben variieren). Apple selber hat den Schadcode bei seinen Eingangskontrollen nicht bemerkt. Das kann jederzeit wieder passieren – plus Apples eigene allgegenwärtige Spitzelei.
Hat irgendwer was anderes erwartet? Viel schlimmer ist das Apple eine eine Kampagne nach der anderen raushaut zum Thema Datenschutz mir iOS 15 aber es scheinbar nur heiße Luft ist.
Und dann kassieren die 1€ für Private Relay was einen auch nicht gut genug schützt, Kennungen können Unternehmen ja weiterhin setzen.
Nun sie machen halt beides. Sammeln Daten und nehmen Geld. Darum ist es so wichtig das unabhängige Stellen hin schauen.
Aber wie Zuboff es schon vor Jahren vorhergesehen hatte: Wenn es möglich ist die Daten zu verwenden, werden sie erhoben und verkauft. Bis es Gesetzlich unter Strafe gestellt wird.
Ist halt nur logisch, das es so kommt. Jeder würde für die selbe Arbeit 100 Euro mehr verdienen wollen wenn, die Daten dabei verkauft werden. So machen es die Konzerne auch. Nur bei denen hat eine Studie schon den Hinweis gegeben das die Menschen ihr Verhalten ändern und vor den Systemen ihr Verhalten ändern damit die Daten nicht anfallen. Wenn diese Wissen das sie überwacht werden. Daher machen es die Unternehmen natürlich insgeheim.
Apple hatte einen besseren Ruf, aber steht nun mal in Konkurrenz zu anderen Überwachungskapitalisten. Daher überrascht es mich nicht.
Aber es könnte auch sein das dies nicht aktiv geprüft wurde und es die App-Entwickler:innen einfach machen weil es mehr Geld bringt.
Libraries die nicht öffentlich sind? Gerade von Google sind diese meistens Open-Source.
Es liegt mehr daran das die Entwicklung eine Menge Aufwand bedeutet und viele Geschäftsführer und Investoren keinerlei Ahnung haben was dies wirklich bedeutet.
Das Entwicker und Teams entsprechend auch die Libraries ausgiebig studieren müssen, die Zwecke und Nutzen testen, ausprobieren und ggf. wieder verwerfen müssen. (Gerade bei Google ist meistens in der Dokumentation erklärt wie man das Tracking ausschalten kann.)
Aber nein, dafür bleibt leider meist keine Zeit, denn die Benutzer wünschen sich die Funktionen, bzw. braucht die App noch diese um auf dem Markt bestehen zu können. Aber welcher Nutzer ist bereit 20€ p. Monat für gute Software auszugeben? „Nein Danke, da kenn ich eine Seite da geht es kostenlos“ – ist bisher immer die Antwort.
Es ist schön das Forscher untersuchen ob derlei Labels stimmen und weiteres, aber die meisten Webbesucher verstehen noch nicht mal was wirklich mit „ID-Nummer“, „Client Informationen“, „Device ID“ wirklich gemeint ist, und was Leute wie ich dann im Hintergrund damit anfangen können um ihnen bessere Werbung anzuzeigen sowie sie zum nächsten Kauf zu bringen.
Wir brauchen keine weiteren EU Regeln von Forschungsgruppen und (veralteten) Richtern, die nur mehr Chaos stiften und noch mehr Druck auf Unternehmen aufbauen. Es braucht Klarheit in der Kommunikation, von Entwicklern die von Anfang an dran denken zu dokumentieren welche Cookies gesetzt werden, bis hin zu Consent Tools die jeder verstehen kann. Was durch die notwendige technische Sprache meist nicht möglich ist, aber nein mir wurde vom Anwalt empfohlen alle Abschnitte mit „leichter Sprache“ aus Sorge vor Abmahnungen wieder zu entfernen.
Und natürlich braucht es Möglichkeiten das Menschen jeglichen Alters es auch richtig verstehen und verstehen lernen – etwas wo vielen Politikern, Anwälten und Richtern besondern gut tun würde.
„Benutzer wünschen sich“
– Manager wünschen sich
– Vorstände wünschen sich
– Investoren wünschen sich
Die Diskrepanz ergibt sich aus Marktmacht, Irreführung, Ausnutzung. „Datensammeln für bessere Werbung“ klingt weniger harmlos, wenn man die Natur strategischer Datensammlung begreift. Spätestens seit Alphabet sollte plastisch vor Augen geführt sein, dass strategische Daten nicht nur für Werbung zu gebrauchen sind, zudem wissen sir doch schon, dass die Marktmacht auch durch Manipulation der Menschen erhalten wird, z.B. indem man Menschen versucht, durch Nutzung von Suchtprinzipien auf den eigenen Diensten Online zu halten. Da ist dann „für bessere Werbung“ bereits ein Euphemismus, der noch getoppt wird, wenn eine Streamingapp eines Namhaften Herstellers, so angekündigt, überprüfen soll, ob Werbung auch wirklich geguckt wird.
Der Verbraucher hat nicht Irreführung bestellt, er wurde in die Irre geführt, und da sind wir schon seit einer Weile. Das Android-Ökosystem ist ein gutes Beispiel für Irreführung by Design. Die bisherigen Regeln der Politik sind, bis auf wenige rühmliche Ausnahmen, Ergebnis der Lobbyarbeit von eben jenen Datenspielern, ihren Nutznießern, sowie weiterer hiesiger kurzsichtiger Größenwahnsinniger.