

Die vergangenen Wochen brannten vor Beschwerden über das angebliche „europäische Bürokratiemonster“ EU-Datenschutz-Grundverordnung (DSGVO), Seehofers Machtspiele um die Asylpolitik sowie die EU-Urheberrechtsreform, die Online-Plattformen zum Einsatz so genannter Upload-Filter verpflichten könnte. Das alles sind natürlich wichtige Themen. Und sie hängen enger zusammen, als der erste Blick vermuten lässt. Dennoch gingen – und gehen – in den Debatten wesentliche Aspekte verloren, vernachlässigt man bei der Betrachtung die Entwicklung von „Algorithmen“ und „Künstlicher Intelligenz“.
Längst haben diese „KI-Technologien“ praktische Relevanz erlangt – unabhängig davon, ob man maschinelle Lernverfahren, Big Data und Quantencomputer als Lösung aller großen Probleme der Menschheit betrachtet oder eine sich verselbständigende Intelligenz und das Ende der Menschheit fürchtet. Es kommt bereits auf die richtige Gestaltung an und die wartet leider nicht auf das Ende der geplanten Enquete-Kommission des deutschen Bundestages, sondern steht bereits jetzt zur Debatte.
Algorithmen und Künstliche Intelligenz: Wo stehen wir?
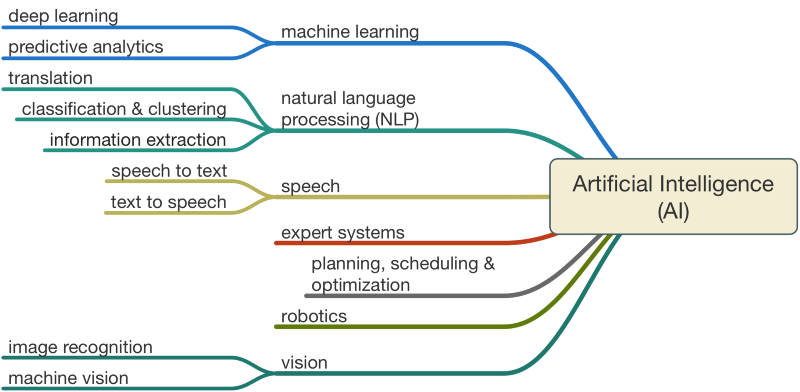
Durchbrüche in einer Reihe an Analysesystemen haben im Zusammenhang mit weltweiter Vernetzung, der massiven Verfügbarkeit von Daten und der exponentiell gewachsenen Rechnerleistung dazu geführt, dass langsam möglich wird, wovon Menschen seit Jahrzehnten träumen: Lernfähige Maschinen. Also smarte Software, die in Verbindung mit steuerungsfähiger Hardware immer mehr Arbeit (Entscheidungen) übernehmen kann, die bislang Menschen vorbehalten war, etwa bei der Analyse komplexer Sachverhalte wie der Identitätsfeststellung eines Menschen, der Bewertung von nationalen Sicherheitsniveaus oder der Steuerung autonomer Waffensysteme. Hoffnungsvoll stimmt natürlich das Versprechen, dass Künstliche Intelligenz dazu beitragen kann, Krankheiten frühzeitig zu identifizieren und zu therapieren. Einen Schreck bekommen die meisten beim Thema „Todesalgorithmus“ – wenn algorithmische Entscheidungssysteme darüber bestimmen sollen, welcher krebskranke Patient welche Therapie erhalten soll. All diese Themen werden an anderer Stelle gerade ausführlich debattiert, aber was hat das Ganze mit der DSGVO, Seehofer und Upload-Filtern zu tun?
Warum die EU-Datenschutz-Grundverordnung von äußerster Bedeutung ist
Bekanntermaßen stellen diese Technologien gesellschaftliche Transparenz und Kontrolle vor große Herausforderungen, in Abhängigkeit von ihrer Komplexität und Dynamik (Übersicht Lösungsansätze). Experten debattierten die Möglichkeiten der so genannten sich-selbst-erklärenden Algorithmen etwa jüngst auf der Cebit. Bei diesen technischen Debatten geht jedoch regelmäßig der Blick für den politisch-ökonomischen Gesamtzusammenhang verloren. Denn es sind eben nicht die Algorithmen, die in neuronalen Netzen ganz unbestimmt nach Zusammenhängen suchen. Sondern Menschen beziehungsweise Unternehmen, die über die Daten verfügen, in denen Suchalgorithmen nach Zusammenhängen suchen – und die vorgeben, welche Daten für welchen Zweck in welcher Breite oder Tiefe durch welche Algorithmen durchforstet werden sollen (Hintergrund). Und die natürlich auch über die Daten verfügen, mithilfe derer algorithmische Systeme geprüft und erklärt werden können. Politisch betrachtet führt das Ganze zu zwei wesentlichen Fragen:
- Wer soll mit welchen Daten KI-Technologien entwickeln, anwenden und überprüfen dürfen?
- Wie lässt sich gewährleisten, dass KI-Technologien auf den „richtigen“ Daten lernen – beispielsweise korrekten, aktuellen, repräsentativen und dem jeweiligen Zweck entsprechende Daten? (Um im Bild von Angela Merkel zu bleiben: Welches Futter braucht die KI-Entwicklung, damit aus den erwünschten Rindern keine Frösche erwachsen?)

Bei beiden Fragen bietet die DSGVO zwar keine erschöpfende Antwort, aber erste Ansätze: Denn einerseits verpflichtet sie Betreiber algorithmischer Entscheidungssysteme in Art. 22 dazu, den so genannten Datensubjekten im Falle einer automatisierten Entscheidungsfindung (inklusive Profiling) Information bezüglich der involvierten Logik eines Entscheidungssystemen, seiner Tragweite und angestrebter Auswirkungen zu geben. Dazu zählt auch das Recht auf menschliche Intervention. Ohne die Kenntnis der Betroffenheit von algorithmischer Entscheidungsfindung und ihrer Logik kann keiner überlegen, ob die Entscheidung korrekt ist oder überprüft oder in Frage gestellt werden muss. Andererseits beinhaltet sie in Art. 13-16 die Rechte, personenbezogene Daten einzusehen, sie zu korrigieren und der Nutzung zu widersprechen – und bietet so eine erste Form der Qualitätssicherung: dass Künstliche Intelligenz auf den “richtigen Daten” lernt. Darüber hinaus verpflichtet sie in Art. 35 die Betreiber algorithmischer Entscheidungssysteme dazu, in Abhängigkeit von den Risiken der Datenverarbeitung eine Datenschutz-Folgeabschätzung zu erstellen – und ein Sicherheitskonzept zu entwickeln, insbesondere für Worst-Cases. Auch das ist sinnvoll, denn jedes algorithmische System kann manipuliert oder gehackt werden.
Nun haben diese positiven Verpflichtungen aber einige Haken: Art. 22 und 35 erstrecken sich beispielsweise nur auf voll-automatisierte Entscheidungen, die meisten Systeme sind jedoch semi-autonom konzipiert. Zudem nutzen neuere Formen des Profiling eher die Daten, die sich aus der Kommunikation und Interaktion von Menschen mit Geräten ergeben als personenbezogene Daten. Dazu gehören etwa Suchanfragen oder Gesprächsinhalte von Messengern – Daten, die nicht von der DSGVO gedeckt sind. Allein deshalb brauchen wir ergänzend die E-Privacy-Verordnung und eine kluge Regulierung von Datenzugangsrechten. Dennoch beinhaltet die DSGVO wesentliche Grundlagen, um die Gestaltung künstlich intelligenter Systeme anzugehen. Sie ist wegweisend.
Warum Seehofer die falsche Sicherheitsdebatte vom Zaun bricht
Während unser Minister für Inneres und Heimat die x-te Asyldebatte vom Zaun bricht und die gesamte Regierung riskiert, scheinen die Risiken von Künstlicher Intelligenz völlig unbeachtet. Dabei berühren sie zentral die nationale Souveränität und Sicherheit der Bevölkerung: Wie etwa eine Schriftliche Anfrage zu Algorithmen in der Bundesverwaltung durch die SPD-Politikerin Saskia Esken im Januar 2018 ans Licht brachte, gibt es laut Bundesregierung keine Kenntnisse darüber, auf Basis welcher Daten die Gesichtserkennungssoftware trainiert wurde, die am Berliner Südkreuz als Gemeinschaftsprojekt des BMI, der Bundespolizei, des Bundeskriminalamts und der Deutschen Bahn AG erprobt wird. Mit dem Verweis auf „Mustererkennung“ scheint alles gesagt – wobei es viele Verfahren gibt, Muster zu erkennen und gravierende Identifikationsfehler.
Leider betrifft die mangelnde Übersicht über eingesetzte Technologien nicht nur den Einzelfall. Sie betrifft auch die Frage, wie weit die gesellschaftliche Steuerung durch Algorithmen bereits entwickelt und in Anwendung ist: Sie ziele auf eine Kontextsteuerung, so der Verwaltungswissenschaftler Klaus Lenk. Statt Zwang und Anreizen soll der Kontext von Menschen technologisch so gestaltet sein, dass sie möglichst automatisch das Richtige tun. Hier wirkten prospektiv verschiedene Technologien zusammen:
- Personalisierung der informationellen Umgebung von Menschen und Organisationen
- Profilbildung für die Zuweisung von Positionen und Lebenschancen
- Verhaltenssteuerung durch technische Architekturen („Nudging“)

Im Endeffekt bekäme man nur das angeboten und zu sehen, was der individuellen Position und ihrer vermeintlichen Bedürfnisse entspricht. Die Beschreibung klingt zwar sehr einleuchtend. Allerdings ist unklar, wo wir stehen: Welche Systeme funktionieren und interagieren wie miteinander? Welche Rolle nehmen hier die Plattformen ein? Wo haben wir es mit Steuerung und wo mit Selbst-Steuerung zu tun? Welche Risiken ergeben sich daraus? Und letztlich: Funktioniert’s überhaupt?
Hintergrund für dieses undurchsichtige Dickicht ist die Tatsache, so der KI-Forscher Matthew Scherer, dass ein Großteil der Entwicklung von Einzelkomponenten (Datensets, Algorithmen, algorithmischen Entscheidungssystemen, Schnittstellen, etc.) in einem bislang unregulierten, internationalen Setting stattfindet, das von einer unüberschaubaren Anzahl von Akteuren bestimmt wird. Da das Potenzial algorithmischer Entscheidungssysteme oft erst im Zusammenwirken dynamischer Technologien zutage tritt, sind Risiken hinsichtlich der Funktionalität und Kontrolle gegeben, die durch mangelnde Verantwortlichkeiten infolge unterschiedlicher territorialer Rechtsbereiche befördert wird. Hier Übersicht herzustellen über sich in der Entwicklung und Anwendung befindliche Technologien, inklusive involvierter Akteure und angemeldeter Patente, scheint wesentliche Voraussetzung für eine adäquate Risikoanalyse – und darauf aufbauend – Strategien der Risiko-Bewältigung.
Vermutlich sollte eine solche Übersicht zu Künstlicher Intelligenz Maßnahmen wie dem staatlichen „Hackback“ oder der Förderung der Interoperabilität von EU-Informationssystemen voraus gehen, zumindest solange EU-Identifikationssysteme 33% Sicherheitsrisiken aufweisen. Sie könnte moderne Formen des E-Government vielleicht sogar unterstützen.
Aber man kann stattdessen auch mit Asylpolitik Stimmung machen.
Warum Upload-Filter eine schlechte Idee sind
Die Debatte um Upload-Filter – um Softwaresysteme, die auf großen Plattformen eingesetzt werden sollen, um die Veröffentlichung von strafbaren Materialien zu verhindern – ist aktuell Gegenstand der EU-Urheberrechtsreform. Auch für die Bekämpfung von terroristischen oder extremistischen Inhalten werden Upload-Filter als scheinbar passables Werkzeug regelmäßig ins Spiel gebracht. Für so manchen Politiker scheint es attraktiv zu sein, unliebsame Inhalte oder Hate Speech schon vor ihrer Veröffentlichung herauszufiltern. Technik wirkt natürlich immer viel neutraler und sauberer als lange Debatten in der Öffentlichkeit.
Aber das Ganze ist nicht unproblematisch: Einerseits können vielfältige Fehler auftauchen, die beispielsweise von Julia Reda im Bereich vermeintlicher Urheberrechtsverletzungen gesammelt und veröffentlicht werden (ganz zu schweigen von den Problemen mit Memes und Satire). Andererseits scheint es gerade im Angesicht dieser Fehler bedenklich, die Meinungs- und Informationsfreiheit schon vor Veröffentlichung und möglicher Beschwerde zu beschränken. Zudem würden durch eine Verpflichtung der Online-Plattformen auf den Einsatz von Upload-Filtern kleinere benachteiligt, welche die hohen Entwicklungskosten entsprechender Software nicht tragen können – und alternativ höchstens durch den Kauf von Software-Lizenzen rechtskonform arbeiten könnten. Das käme einer weiteren Monopolisierung der Plattformindustrie gleich.

Unterbeleuchtet bleibt auch hier die Rolle Künstlicher Intelligenz: Sie soll mit selbst-lernenden Algorithmen durch die Analyse großer Mengen an Daten dazu beitragen, neue Erkenntnisse zu generieren. Neue Erkenntnisse erlauben neue Strategien und tragen damit zu einem Wandel von Normen und Werten bei. Man muss nicht einmal den Sieg von Alpha Go! über den Menschen berücksichtigen, um die Bedeutung „maschineller Kreativität“ zu entdecken. Eigentlich reicht das logische Durchdenken aktueller Probleme: Wenn 10.000 Kommentare als Hate Speech gelabelt werden oder 10.000 Kommentare wie bei Jigsaw (Alphabet Inc.) in einer Toxizitätsskala danach verortet werden, wie hoch das Risiko ist, dass ein Teilnehmer die Debatte verlässt: Welche Zusammenhänge lernt eine Maschine, wonach entscheidet sie? Wahrscheinlich verschiebt sich der Fokus von der Idee hin zur Sprache, zum Ausdruck an sich. Möglicherweise kommen aber ganz andere Variablen ins Spiel – Variablen, über deren Angemessenheit Techniker und Geschäftsleute entscheiden anstelle von Richtern, Politikern oder Soziologen. Kann eine derart erwachsene maschinelle Entscheidung über Grundrechte legitim sein?
Die Gesellschaft als lebendiges Experimentierfeld
Alle großen Plattformen experimentieren derzeit mit Formen automatisierter Inhalte-Regulierung in verschiedenen thematischen und medialen Bereichen, die mitunter ganz neue Erkenntnisse über menschliche Debatten und Interventionsmöglichkeiten generieren dürfte. Aber wie gesagt: Zum gegenwärtigen Zeitpunkt ist all dies noch (hoch-)experimentell. So schätzte Facebook-Chef Mark Zuckerberg bei seinen Anhörungen zum Cambridge-Analytica-Skandal im US-Kongress gleichermaßen optimistisch wie unscharf, es dauere noch rund 5-10 Jahre, bis Facebook „Hassrede“ zuverlässig erkennen könne. Wie kann es dann sinnvoll oder gerechtfertigt sein, Online-Plattformen zum jetzigen Zeitpunkt auf Upload-Filter samt KI zu verpflichten – wo doch noch gar nicht klar ist, was deren Ergebnis ist? Wäre es nicht sinnvoll, die Plattformen zunächst zu Transparenz hinsichtlich ihrer Funktionsweise, Sicherheitsrisiken und Bewältigungsmaßnahmen zu verpflichten und in einen Dialog zu treten mit Legislative und Judikative, um die Chancen und Risiken automatisierter Inhalte-Regulierung zu eruieren? Und so lange beim altbewährten (und mittlerweile technisch gut unterstützen) Notice-and-Take-Down-Verfahren zu bleiben? Immerhin: Wir leben in einem Informationskrieg, der gerade durch fehlende Verantwortlichkeiten übelste Blüten trägt und durch falsche Reaktionen noch viel schlimmer werden kann. Ist die Urheberrechtsindustrie tatsächlich willens, die Zerstörung demokratischer Debatten und Nationalstaaten auf ihre Kappe nehmen? I wouldn’t.
Es ist längst überfällig, dass die drängenden Themen eine adäquate demokratische Bearbeitung finden durch die Bundesregierung, EU-Kommission, Bundestag und EU-Parlament. Dass überholte Machtkonflikte und kurzsichtige Wahlkampfmanöver mal beiseite gelegt werden könnten, damit die Themen Platz finden, die jetzt schon über das Schicksal zukünftiger Generationen bestimmen. Sicher gibt es mehr als Algorithmen und Künstliche Intelligenz. Aber sie wirken schon seit geraumer Zeit überall hinein und sollten entsprechende Berücksichtigung finden. Stellen wir die Weichen nicht rasch und gemeinsam, wird’s allein der Markt richten. Zu seinen Gunsten, nicht zu unseren.



{kind=link}
Ich bin bei dem Thema eher bei Musk, aber nur insoweit er sagt, KI wäre gefährlich. In der Regulierung sehe ich keine Lösung des Problems, denn auch hier wird die Entwicklung in der sinnbildlichen Garage passieren. Und in Garagen wirkt Regulierung nicht. Wenn diese echte KI also aus der Garage heraus in die frei Wildbahn entwischt, hilft die schönste Regulierung nichts. Oder gibt es Nerds, die erst alle rechtlichen Regularien um ihre Spielereien und Tests drumherumbauen und dann ihre eigentliche Idee verfolgen.
Deutschland ist in den letzten Monaten deutlich irrational geworden. Die KI ist nichts anderes als ein von den Politikern verbreiteter Unsinn in den Medien.
Ein intelligenter Mensch weiß, dass nur Roboter mit Gehirn der Menschheit die Chance geben können wirklich gerechte und funktionierende Gesellschaft zu bauen. Der Mensch alleine ist unfähig diesen Planeten im 21. Jahrhundert selbst zu steuern.
Die Gefahr, dass der Computer so wird wie der Mensch, ist nicht so groß wie die Gefahr, dass der Mensch so wird wie der Computer.
Konrad Zuse
„Praktische Anwendung finden nicht die richtigsten, sondern die einfachsten Theorien.“
„Not the most correct, but the least complicated theories find practical application.“
Konrad Zuse. So zu lesen vor dem früheren Bundesministerium des Innern.
https://blog.fefe.de/?ts=a5d4c2a9
Sowas könnte man sich kaum ausdenken.
Vielleicht ist es ja an der Zeit, mal darauf hinzuweisen, daß es in höchstem Maße leichtfertig ist, Maschinen Entscheidungen zu überlassen.
„Die Maschine wars, da kann man halt nix machen“ ist sonst das neue „wir hatten unsere Befehle“.
Ja, das dachte ich auch mal. Heute denke ich, dass wenn in manchen Bundesländern (ich erinnere mich immer an die Zahl 80%, muss die Quelle aber noch wieder finden) massiv Staatsanwälte, Lehrer oder Ärzte fehlen, dass man nicht darum herum kommt, zumindest bei Standardfällen algorithmische Entscheidungssysteme zur Entscheidungsunterstützung einzusetzen. Auch im Bereich der Daseinsfürsorge – wenn man derzeitige Level halten will und weniger Steuern rein kommen.
Das hat mich zu verschiedenen Schlüssen gebracht:
1) Wenn man es tun muss, muss man es möglichst gut tun – und zwar jetzt. Das stellt einige Herausforderungen an die Technik, Daten, Verantwortliche usw.
2) Wenn man bei dem Ganzen reale Optionen menschlicher Intervention erhalten will, braucht man gute Mensch-Maschine-Schnittstellen – die verschiedene Optionen algorithmischer Entscheidungsfindung sichtbar machen (z.B. Lebenserwartung und -qualität krebskranker Patienten in Abhängigkeit von Therapie, Chemotherapie, Homöopathie usw. mit den verschiedenen Wahrscheinlichkeitsgraden …) und Auswahl ermöglichen.
Bei der Aktionärsversammlung vom 31.5.18 wurde Zuckerberg und andere CEOs von recht besorgten „Shareholders“ u.a. gefragt, ob FB es schaffe alle Fake Accounts (!) zu löschen, denn 4 Individuen (aus Russland) hätten gereicht so viele Fake Accounts zu generieren um damit die US-Präsidentenwahl beeinflussen zu können. Daraufhin antwortete Zuckerberg, ich sag mal versuchend ausweichend, daß sie es eigentlich (vom Design, System her?) nicht schaffen Fake Accounts von vornherein zu löschen und sich somit ca. 4% Fake-Accounts immer finden lassen – die aber (natürlich!) im Laufe der Entwicklung neuer Tools immer schneller identifiziert und gebannt werden würden.
4% Fehlerquote bei Massenüberwachung – a priori: Wetten das man ausgerechnet die gute alte Mafia als solche bei denen nicht findet – also, eher im Gegenteil – die sind da die besten Menschen auf der Welt. Nicht wahr?
Da die schon lange nicht mehr (selber) lesen: 1985 kam der Film „Brazil“ von Terry Gilliam raus: Vielleicht kann man denen ja noch damit bespielte (geraubtkopierte) VHS-Kassetten um die Ohren werfen. (VHS war das schlechteste Video-System aller Zeiten – diese Quali hätten die verdient.)
Naja, jedenfalls hat das US Verteidigungsministerium gerade einen Wettbewerb ausgeschrieben, 1. wer kann die besten (technischen) Fakes? und 2. wer kann die besten (technischen) Fakes erkennen?
https://www.heise.de/newsticker/meldung/DARPA-veranstaltet-Wettbewerb-zu-Faelschung-von-Video-Inhalten-4074467.html
Was das Thema Lüge und Wahrheit im gesellschaftlichen Diskurs angeht, nun, da testet Facebook wohl Verschiedenes. Eine Lösungsoption wäre es, Nutzer und Quellen zu ranken, ob sie „trustworthy“ sind:
https://netzpolitik.org/2017/wie-man-den-hass-schuert-risiken-privatisierter-rechtsdurchsetzung/
https://netzpolitik.org/2018/kommentar-die-oeffentliche-meinungsbildung-wird-fuer-facebook-zum-experimentierfeld/
Muss man mal alles beobachten …
„Zudem nutzen neuere Formen des Profiling eher die Daten, die sich aus der Kommunikation und Interaktion von Menschen mit Geräten ergeben als personenbezogene Daten. Dazu gehören etwa Suchanfragen oder Gesprächsinhalte von Messengern – Daten, die nicht von der DSGVO gedeckt sind“.
Die Passage scheint mir recht unglücklich formuliert.
Satz 1: „Nutzen neueren Formen des Profiling die Daten als [als = ‚Kommunikations- und Interaktionsdaten werden als – Unterform von? – personenbezogene Daten genutzt‘ oder als = ‚eher, als…‘?] personenbezogene Daten (…)“
Satz 2: Suchanfragen und Gesprächsinhalte von Messengern sind nicht von der DS-GVO gedeckt? A.A. vertretbar.
Satz 1: = eher, als
Satz 2: leider nein, dafür war von Anfang an die E-Privacy-Verordnung gedacht, die die Datenschutz-Grundverordnung ergänzen und zeitlich mit ihr in Kraft treten sollte: https://netzpolitik.org/2017/sechs-gruende-warum-die-totlangweilig-klingende-eprivacy-verordnung-fuer-dich-wichtig-ist/
sry der Kürze, bei Bedarf später mehr
So, hier noch ein guter Link, ich muss auch immer wieder mal nachschauen: https://netzpolitik.org/2017/eprivacy-was-die-eu-dieses-jahr-fuer-privatsphaere-und-kommunikationsfreiheit-tun-kann/
Die Sache ist: Es gab zwar schon eine E-Privacy-Richtlinie, die galt aber nicht für Messenger und Internet-Telefonie, weil es das noch nicht so lange gibt. Die galt nur für SMS und Telefonie. Naja, mehr steht im Artikel. Danke Ingo!
Leider wird die Debatte über KI komplett falsch geführt, weil die Medien und Politiker ein Bild gezeichnet haben, dass nicht zutrifft. Zuallererst wäre es notwendig, dass Journalisten und Politiker eine angemessene Skepsis gegenüber des Marketings von den entsprechenden Akteuren aufbringen. Facebook, Tesla und IBM verkaufen „künstliche Intelligenz“ so als ob KI in der Lage wäre zu Verstehen oder gar über Bewusstsein verfügt. Das ist natürlich großer Quatsch, KI ist ist nichts weiter als automatisierte Statistik.
Es lässt sich viel Geld damit verdienen solche Bilder zu zeichnen und die Erwartungen zu schüren, die dann irgendwann nur zur Enttäuschung führen. Diese Erwartungen sind aber auch die Ursache für Angst vor künstlicher Intelligenz, insbesondere von Leute, die gar nicht verstehen wie es wirklich funktioniert. Fragt doch mal die KI Forscher auf Fachkonferenzen, anstatt sich von irgendwelchen hippen Marketignkeynotes berieseln zu lassen. Aber das ist ja zu anstrengend, man müsste ja versuchen zu verstehen, wie das funktioniert und in Mathe war man doch immer so schlecht.
Politiker und Soziologen oder allgemein Geisteswissenschaftler stützen sich auf Daten und beweisen empirisch. Genau das macht die Maschine auch, nur eben neutral und objektiv, solange die Daten das hergeben. Das ist natürlich Gift für den Geisteswissenschaftler, der im Normalfall seine Statistik so anpasst, dass das heraus kommt, was politisch korrekt wäre.
Nein Angst vor KI hilft uns nicht und Nein auch die DSGVO hilft uns nicht. Es sind die Reaktionen von Politikern und Journalisten auf eine Welt, die Sie nicht verstehen (wollen). Fortschritt konnte aber noch nie aufgehalten werden, er findet nur wo anders statt.
Du hast Machine Learning nicht verstanden. Da wird „gut“ oder „schlecht“ im Rahmen des Trainings vorgegeben, und die Loesungsfindung der Maschine ist mindestens so biased wie das Training. Mindestens, denn die Maschine kann uns noch unbekannte oder abwegig erscheinende Korrelationen als Vorurteile ausbilden.
Ich arbeite zwar über 5 Jahre mit maschinellem Lernen und wende die verschiedensten Verfahren im täglichen Job an, aber natürlich habe ich es nicht verstanden, ist klar. Ich habe außerdem nicht in Frage gestellt, dass eine Datenbasis biased sein kann.
Nicht nur die Datenbasis kann biased sein, auch die Ergebnisgewichtung. Das ist genau der Punkt, den ITler gerne nicht sehen oder nicht sehen wollen, denn sie haengen dem heiligen Gral der objektiv optimalen Entscheidung in allen Fragen an. Weswegen sie uebrigens auch gerne totalitaere Tendenzen haben, diese vermeintlich objektive Wahrheit durchzusetzen.
Erst die Unterstellung ich hätte Maschinelles Lernen nicht verstanden, jetzt gleich die nächste Unterstellung. Du scheinst mich ja gut zu kennen.
… mir scheint …
… ich habe den Eindruck, dass …
… korrigiere mich, wenn ich falsch liege …
… es wäre so schade, wenn die wenigen, die die Sache ernsthaft betreiben, verstehen wollen, versehentlich im Mißverständnis enden. Meistens fehlt nur der Kontext für das richtige Verständnis, den muss man halt erklären … Danke für die vielen Kommentare von allen!
@h s @Sven
Bitte zitieren Sie genauer die relevanten oder aus ihrer Sicht nicht zulässigen Stellen und
@h s
Worte mit „Du“ anfangen sind direkte Meinungen über den anderen und im negativen Kontext meist persönlich formuliert.
Kritisieren Sie besser die Sachäußerung oder reden Sie von ihren Emotionen, wenn Sie den entsprechenden Eindruck haben.
Das ist grundsätzlich empathischer, weil es dem anderen keine Position unterstellt, sondern ihren Eindruck wiedergibt.
„auch die Ergebnisgewichtung“
Die Ergebnisgewichtung sollte als Matrix vorliegen und hängt jeweils von den zufällig gewählten Beispielen ab und deren Auswirkung auf die Netzkonstruktion und/oder Berechnungsfunktion je nach Methode.
https://www.researchgate.net/post/Whenever_i_run_my_neural_network_I_get_different_result
Meinen Sie vielleicht die unterschiedliche Initialgewichtung und Beispielziehung?
Ergebnisgewichtung als Begrifflichkeit ist mir nicht bekannt.
Einfach nur: Danke für den Artikel ! Ein weiterer Schritt aus dem (meinem) Diffusen heraus.
Die derzeitige Politiklinie verfolgt in grossen Teilen den Rueckzug des Staates, Stichwort marktkonforme Demokratie, und hat gar kein Interesse daran, Zukunft zu gestalten. Das ueberlaesst man dem Markt, also den Eliten der neuen Feudalordnung.
Die meisten dieser Politiker duerften erleichtert sein, wenn in Zukunft noch mehr „alternativlose Sachzwaenge“ und Automatismen den Weg vorgeben und vom Buerger akzeptiert werden. Zumal die ganz zufaellig idR im Sinne besagter Eliten agieren werden.
Ergaenzend: fuer die konservativen wie fuer die neoliberalen Parteien ist dieses Vorgehen der Gestaltungsverweigerung fundamentaler Teil ihres Programms. Da verhallen alle Aufrufe im Nichts, denn da wird kein Fehler gesehen. Die etablierten Eliten in Wirtschaft und Medien sehen dem noch recht gelassen entgegen, denn sie gehen davon aus, dass sie das in ihrem Sinne beherrschen werden.
Die SPD kommt aus einer anderen historischen Tradition, hat das aber durch die Tradition des Umfallens und Realitaetsverleugnens ersetzt, da ist absehbar nichts zu erwarten.
Wie sagt Freund Wetter immer: „Erstmal gucken, dann mal schauen …“
Algorithmen und Künstliche Intelligenz
Repräsentatives Lernen von Wiedererkennung von Mustern begrenzter Größe in Daten durch Vorgabe der aus Beispielklassen funktioniert gut.
Daraus Schlüsse ziehen oder diese wiederzubenutzen funktioniert nur mäßig.
Rekursive Programme oder Strukturen lernen: äußerst begrenzte Rekursionstiefe
Zur Erkennung von falschen/mutwillig veränderten Daten
–> Die Güte von Daten für sich kann man nur manuell überprüfen
–> Wenn man logische Formeln extrahieren kann als Programm, kann man diese verifizieren, weil man dann weiß, dass das richtige Programm gelernt wurde.
–>Alternative kann man per SMT-solver das Programmverhalten überapproximieren, was aber eine aufwendige Spezifikationserstellung umfasst.
2. Punkt: Solange man da gar nichts macht und so dermaßen in der technischen Umsetzung versagt, ist das erstmal nicht wichtig. Sobald aber es da Fortschritte gibt, ist es wichtig.
3.Punkt Zerstörung der einhergehenden Meinungsübersicht wird zu massivem Anwachsen von Populismus (Worte oder Formulierungen werden verboten oder Leute willkürlich zensiert) führen, also exakt dem, was man damit vorbeugen möchte
Selbst in China wird das nicht automatisch gemacht, weil man damit die Kontrolle über die Netze abgibt. Ferner sieht man dort, dass man dann kreativ bei der Umschreibung und Kommunikation von Kritik wird.
4.Wesentliche technische Probleme, die es unwahrscheinlich machen die PR-Versprechen von facebook einzulösen:
Punkt KI kann die Semantik von Worten als Realitätsbeschreibung des Menschen nicht erfassen und wird das nur mit extremen Aufwand seitens der Firmen was die Axiomatisierung von Objektfunktionalität oder Wortstammanalyse betrifft machen können.
Durchbrüche dahingehend sind mir zur Zeit noch nicht bekannt und ferner kann man Begriffsbeschreibungen beliebig erweitern.
Eine zuverlässige Erkennung von Ironie, Sarkasmus und Zynismus kann man und wird man (weil es Menschen selbst oft nicht erkennen) auch nicht bald erkennen können.
Ferner müsste man den sich wandelnden Kontext von Begriffen in der KI erfassen, der Menschen ohne Vorlage der geschichtlichen Zeittexte selber nicht klar wird.