Ende Juni klingelt Dirk Brockmanns Telefon. Lothar Wieler ist dran: „Herr Brockmann, sehen wir Gütersloh?“ Wieler ist Chef des Robert-Koch-Instituts und damit auch Chef von Brockmann, dessen Arbeitsgruppe am RKI mathematische Modelle von Epidemien baut. Und Wieler will nun wissen, ob er in seinen Daten den aktuellen Ausbruch rund um den Fleischkonzern Tönnies erkennen kann, der zu einem Lockdown für den gesamten Kreis führte. Doch Brockmann und sein Team sehen: nichts.
Vielleicht heißt das: noch nichts. Weil der Erkennungsalgorithmus noch nicht fein genug justiert ist. Vielleicht werden sie nie ein Signal erkennen können in den Daten, die ihnen mehr als 500.000 Menschen in Deutschland über ein App täglich zukommen lassen.
Brockmann und seine Arbeitsgruppe betreiben am RKi Grundlagenforschung. Normalerweise interessiert das vor allem andere Wissenschaftler:innen aus diesem Fachgebiet, das sich „digitale Epidemiologie“ nennt. Doch seit Brockmann Anfang April die Idee zu einer Datenspende-App am Institut durchsetzte, stehen er und sein Team in der Öffentlichkeit.
Ein Erfolg und ein Haufen Ärger
Auf den ersten Blick ist das Projekt schon jetzt ein Erfolg. Mehr als eine halbe Million Menschen haben zugestimmt, dem Institut sehr persönliche Daten zu ihrem Körper zu überlassen. Sie messen ohnehin schon ihren Puls und ihre Schrittzahl mit Hilfe von tragbaren Sensoren am Körper, so genannten Fitnesstrackern. Diese Informationen teilen sie nun über eine App mit dem RKI, täglich.
Brockmann glaubt, dass sich in den Daten Muster erkennen lassen. Denn wenn der durchschnittliche Ruhepuls einer Person über mehrere Tage ansteigt, dann kann das auf Fieber hindeuten. Anhand der gespendeten Daten lässt sich so womöglich ein Werkzeug bauen, mit dem man einen Anstieg der durchschnittlichen Körpertemperatur in einer bestimmten Region messen kann – und damit ein Frühwarnsystem für neue Covid-19-Ausbrüche, noch bevor das Gesundheitsamt diese mitbekommt.
Die Datenspende „ermöglicht uns, die Ausbreitung des Coronavirus besser zu erfassen und die Dunkelziffer der Infizierten drastisch zu verringern“, sagte Brockmann vor der Veröffentlichung der ersten Ergebnisse im Mai. „Diese Informationen sind für Epidemiologen unglaublich wertvoll und helfen, bessere Maßnahmen abzuleiten.“
So viel zur Theorie. In der Praxis macht die Sache Brockmann und seinem Team bislang vor allem viel Arbeit und Ärger. Weil das RKI die App am 7. April weitgehend ohne Ankündigung veröffentlichte während alle auf die angekündigte Corona-Warn-App warteten, sorgte ihr Erscheinen vor allem für Irritation. Noch dazu war die App nicht quelloffen. So war von außen nicht zu überprüfen, ob all die Versprechungen zum verantwortlichen Umgang mit den sensiblen Daten auch eingehalten wurden.
Die Gesellschaft für Informatik bemerkte damals, die Anwendung erfülle in Hinblick auf Datenschutz und IT-Sicherheit nicht die grundlegenden Anforderungen. Die App sei „überraschend schlecht gemacht und daher dem Schutz der Bevölkerung eher abträglich“. Der Tiefpunkt folgte kurz darauf, als IT-Fachleute des Chaos Computer Club die App abklopften und dabei zahlreiche Datenschutz-Katastrophen fanden.
„Einfach nur anstrengend“ sei das Projekt zeitweise gewesen, sagt Brockmann in seinem Büro im zweiten Stock des RKI. Erst kam die fachliche Kritik, dann spürten er und seine Mitarbeiter:innen den politischen Druck, etwas abliefern zu müssen. Er denkt, die App würde bald wieder abgeschaltet werden, sollten sie nicht bald Ergebnisse vorzeigen können. Die Datensammlung sei aber ein „exploratives Projekt“ mit ungewissem Ausgang. „Bei allen Projekten, die ich anfange, liegt die Wahrscheinlichkeit, dass das nichts wird bei 95 Prozent.“
Eine erste grobe Kurve zeichnet sich ab
Zumindest in diesem Fall besteht aber die Chance, dass doch noch etwas daraus wird. Nach ersten Ergebnissen zur regionalen Verteilung der Spender:innen und den durchschnittlichen Ruhepuls-Werten pro Landkreis veröffentlichte Brockmanns Team am Wochenende eine erste, grobe Fieberkurve.
Grob ist sie deshalb, weil es gar nicht so leicht ist, aus den Messungen etwas zu erkennen. Jeden Tag landen Daten der Spender:innen auf dem Server des RKI: der durchschnittliche Ruhepuls, die Schrittzahl pro Tag, bei manchen auch die Schlafdauer und weitere Angaben zu Gewicht, Alter und Geschlecht. Rund 170.000 Menschen hätten fast an jedem einzelnen Tag der vergangenen drei Monate Daten gespendet, sagt Brockmann. Diese lange Dauer ist deswegen wichtig, weil die Wissenschaftler:innen erst die Normalwerte für eine Person ermitteln müssen bevor sie Abweichungen davon feststellen können.
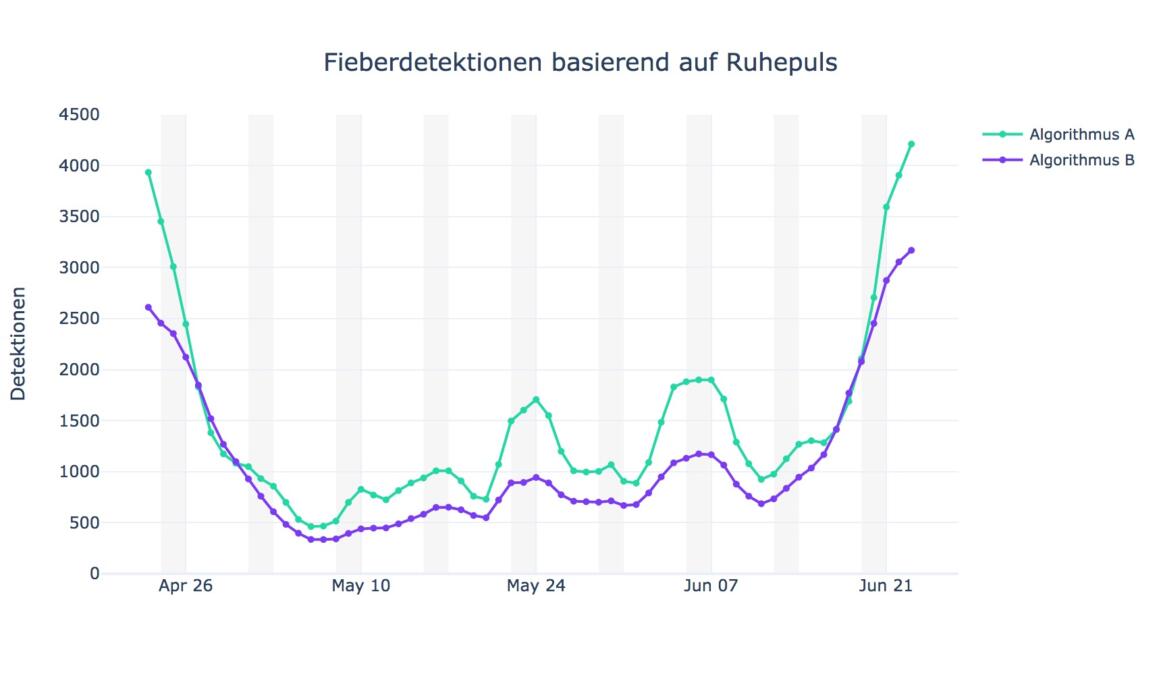
Doch der Ruhepuls allein, das zeigte sich nach ersten Auswertungen, reichte nicht aus, um Fieber zu erkennen. Das fiel den Forscher:innen auf, als Ende Juni plötzlich überall in Deutschland die Kurven nach oben deuteten. War hier eine neue Corona-Welle zu sehen? Erst als sie die tägliche Schrittzahl für eine feinere Analyse mit einbezogen, zeigte sich: Der Puls geht hoch, weil die Menschen sich mehr bewegen. Das kann an der beginnenden Urlaubssaison liegen oder am guten Wetter.
Solche Verzerrungen, sagt Brockmann, seien in „natürlichen Experimenten“ normal. Sie herauszurechnen und darunter die Effekte freizulegen, die man tatsächlich sucht, das kostet die Forscher:innen gerade viel Mühe.
Inzwischen arbeitet das Team mit einem Algorithmus, der die durchschnittlichen Pulsdaten mit der täglichen Schrittzahl kombiniert und die Kurve so von falschen Treffern bereinigt. Erst wenn der Puls hochgeht während sich jemand zugleich deutlich weniger bewegt wird der Datensatz als Fieber-verdächtig markiert.
Zur Kontrolle legt das Team diese Kurven auf andere Daten, die das RKI etwa aus dem „Grippeweb“ zieht. Dieses Datenspendeprojekt, bei dem Teilnehmer:innen im Wochenrhythmus melden, ob sie Husten oder Schnupfen hatten, ist wesentlich älter und weniger bekannt, dafür läuft es solide.

CCC-Fachleute fanden viele Sicherheitslücken
Die Fitnesstracker-Daten, die das Team auswertet, landen zunächst auf einem Server der Firma Thryve: ein Berliner Gesundheits-Startup, das die App entwickelte und für das RKI betreibt. Die vielen Kritikpunkte, die CCC-Experten an der App übten, sie beziehen sich vor allem auf die Methoden, mit denen Thryve die Daten einsammelte und speicherte. Unter anderem stellte sich bei der Analyse heraus, dass die pseudonymisierten Daten – anders als dargestellt – nicht von den Smartphones selbst stammen. In vielen Fällen lagen sie auf den Servern der Firmen, die die Tracker herstellen. Die Spender:innen erteilten Thryve die Zustimmung, auf ihre Nutzerkonten dort zuzugreifen.
So konnte das Unternehmen in einigen Fällen auch den Vor- und Nachnamen sehen und Daten bis weit vor dem Zeitpunkt, ab dem sie der Datenspende zugestimmt hatten. Eine ziemliche Katastrophe für eine App, die Datenschutz verspricht, denn damit ließen sich die gespendeten Pulsdaten einzelnen Personen zuordnen, über deren Lebensgewohnheiten und Gesundheitszustand sich einiges ableiten lässt.
Hat Thryve diese Probleme inzwischen gelöst? Ein Teil der Sicherheitslücken, sagt Thryve-Sprecher Sebastian Wochnik am Telefon, seien nach dem Hinweis der CCC-Autoren schon vor der Veröffentlichung ihres Berichts Mitte April behoben worden, etwa die Angriffsfläche des Servers, auf dem die sensiblen Daten lagern.
Das größte Problem, den Zugang zu den Namen und damit eine klare Zuordnung der Daten zu einer Person, konnte Thryve aber nur mit dem digitalen Holzhammer lösen. Weil die Hersteller der verschiedenen Fitnessarmbänder den Blick in die Konten der Nutzer:innen nicht auf Alter, Geschlecht oder Gewicht beschränken können, hat die Firma diese Abfrage komplett eingestellt. „Nur so konnten wir vermeiden, dass wir Namen speichern könnten, die wir ja gar nicht haben wollen“, sagt Wochnik.
In Zukunft sollen Spender:innen die Angaben zu Alter oder Geschlecht einfach von Hand in die App eintragen können, wenn sie sie denn teilen wollen. Etwa jede zehnte Person tut das bislang, schreiben die Forscher:innen in ihrem Projektblog. Wie schwer jemand ist oder welches Geschlecht sie hat, dieses Wissen ist nicht notwendig, um Fieber oder eine Covid-19-Infektion zu erkennen. Es zeigt aber, die stark die Summe der Spender:innen von einer repräsentativen Stichprobe der Bevölkerung abweicht – ein weitere Verzerrung, die korrigiert werden muss.
Weiter Zugriff auf historische Daten
Was Thryve hingegen nicht lösen konnte: Den Blick auf die Daten auch aus einem Zeitraum bevor die Spender:innen dem zugestimmt haben. Diese „historischen Daten“ würden bewusst nicht abgerufen, sagt Wochnik. Theoretisch könne die Firma aber über den Zugang zu den Konten weiterhin auf sie zugreifen.
Die Nutzer:innen der App scheinen all die Versäumnisse nicht zu stören, zumindest schicken sie ihre Daten weiterhin an Thryve und das RKI. Ob sich das „natürliche Experiment“ am Ende gelohnt haben wird, weil die Datenspenden tatsächlich dabei helfen, Covid-19-Infektionen aufzudecken? Als Brockmann die Idee entwickelte, war noch nicht bekannt, wie viele Infektionen gänzlich symptomfrei verlaufen. Außerdem liegt die Zahl der Neuinfektionen derzeit einfach zu niedrig. Vielleicht werden Brockmann und sein Team am Ende mit den Daten von mehr als 500.000 Menschen ein Werkzeug entwickelt haben, um die Häufung von Fieber auf Landkreisebene zu erkennen. Das wäre beachtlich, hätte aber als Maßnahme gegen die Pandemie nicht viel gebracht.