

Georg Ahnert studiert Computational Social Systems an der RWTH Aachen. Er forscht zur Wahrnehmung von Gerechtigkeit maschineller Entscheidungen und hat gemeinsam mit anderen ein Framework zur empirischen Erhebung dieser Wahrnehmungen entwickelt.
Maschinen haben bereits heute einen großen Einfluss auf Entscheidungen über zum Beispiel die Kreditwürdigkeit einer Person, den Umfang ihrer Förderung bei Arbeitslosigkeit, oder ob eine Haftstrafe auf Bewährung ausgesetzt wird. Für letztere Entscheidung wird maßgeblich das Risiko der Strafrückfälligkeit zu Grunde gelegt. Die in den USA weit verbreitete Software COMPAS versucht dieses Risiko vorherzusagen. Sie ist aber nach einem Artikel von ProPublica zu einem beliebten Beispiel von maschineller Diskriminierung geworden, da sie schwarzen Menschen eine höhere Risikobewertung erteilte als weißen Menschen. Der Hersteller von COMPAS, Northpointe, argumentierte darauf hin, dass gängige Gerechtigkeitsanforderungen erfüllt würden, und zweifelte die Analyse von ProPublica an.
Widersprüchliche Gerechtigkeitsdefinitionen
ProPublica vergleicht die falschen Vorhersagen von COMPAS für weiße und schwarze Angeklagte. Dabei stellt sich heraus, dass es bei Weißen häufiger vorkam, dass COMPAS sie als „geringes Risiko“ einschätzte, sie aber dennoch strafrückfällig wurden. Im Gegensatz dazu wurde Schwarzen eher ein „hohes Risiko“ vorhergesagt, auch wenn sie nicht rückfällig wurden. Der Algorithmus unterschätzte also die Rückfälligkeit von Weißen und überschätzte die Rückfälligkeit von Schwarzen. Der Vergleich von ProPublica ist plausibel und relevant.
Northpointe hingegen führt andere Definitionen von Gerechtigkeit an, um zu argumentieren, weshalb der Algorithmus Schwarze nicht diskriminiere. Zum Beispiel war der Anteil an korrekt vorhergesagter Rückfälligkeit für weiße und schwarze Hochrisiko-Straftäter:innen gleich, ebenso wie die Gesamtgenauigkeit des Algorithmus für weiße und schwarze Straftäter:innen. Der ProPublica-Artikel hat eine Diskussion über maschinelle Entscheidungen ausgelöst. Spätere Forschung zeigte, dass COMPAS kaum bessere Vorhersagen traf als unerfahrene Menschen oder ein deutlich einfacherer Algorithmus, der nur „Alter“ und „Anzahl an bisherigen Verurteilungen“ zu Grunde legt.
Nichtsdestotrotz sind die Angaben von Northpointe zur Gerechtigkeit von COMPAS korrekt und ebenfalls relevant. Diskriminierte COMPAS Afroamerikaner also doch nicht? Leider lässt sich die Frage nicht so einfach beantworten, denn tatsächlich ist es gar nicht möglich, sowohl die Gerechtigkeitdefinition von ProPublica als auch die von Northpointe gleichzeitig zu erfüllen. Das liegt daran, dass die durchschnittliche Rückfallquote für schwarze und weiße Straftäter :innen unterschiedlich ist, sowohl in Broward County, dessen Daten die Grundlage für ProPublicas Analyse bildeten, als auch in den USA allgemein. Jede:r Entscheider:in, ob Mensch oder Maschine, muss verschiedene Definitionen von Gerechtigkeit also gegeneinander abwiegen und COMPAS stellt nur eine mögliche solche Abwägung dar.
Discrimination In – Discrimination Out
Um den Konflikt verschiedener Gerechtigkeitdefinitionen besser zu verstehen, lohnt es sich anzuschauen, weshalb Diskriminierung überhaupt ein Problem maschineller Entscheidungsfindung ist. Dabei sind besonders automatisierte Systeme relevant, die ihre Entscheidungen anhand von aus Daten gelernten Mustern treffen, wie das bei COMPAS oder auch dem österreichischen Arbeitsmarktservice-Algorithmus der Fall ist.
In ihrem Buch Responsible Machine Learning beschreiben Patrick Hall, Navdeep Gill und Benjamin Cox vier Wege, auf denen sich Diskriminierung in maschinelles Lernen einschleichen kann:
- Falsche Problemstellungen versuchen zwischen unpassenden Datensätzen Zusammenhänge zu erkennen (möglicherweise zum Beispiel zwischen Vorstellungsvideos und Persönlichkeit).
- Fehler beim Kodieren treten auf, wenn zum Beispiel Hautfarbe als Nummer kodiert wird und dadurch plötzlich eine „doppelt so viel wert ist“ wie eine andere.
- Nicht repräsentative Daten können Diskriminierung hervorrufen, wenn etwa überproportional viele Fälle von schwarzen Straftäter:innen vorliegen oder überproportional viele von weißen.
Die ersten drei Kategorien von Problemen lassen sich technisch beheben, indem bessere Daten erhoben werden, diese besser vorbereitet werden und unzulässige Fragestellungen gestrichen werden. Hinzu kommt aber das Problem akkurater Daten, die historische Verzerrungen wiedergeben. Diese können zum Beispiel aus den Auswirkungen traditioneller Rollenbilder entstehen, direkt Fälle von Diskriminierung oder deren Folgen beinhalten. Ein solcher Unterschied wurde ja zum Beispiel zwischen der Strafrückfälligkeit schwarzer und weißer Straftäter:innen in ProPublicas COMPAS-Datensatz deutlich.
In der Folge kann sich Diskriminierung laut Hall, Gill und Cox auf folgende vier Arten in den Ergebnissen von maschinellem Lernen niederschlagen:
- Bei expliziter Diskriminierung wird die Zugehörigkeit zu einer Gruppe direkt zur Vorhersage ungleicher Ergebnisse genutzt.
- Bei ungleichen Gruppenergebnissen werden Zusammenhänge zwischen Gruppenzugehörigkeit und Ergebnissen gelernt und führen so zu schlechteren Ergebnissen für historisch benachteiligte Gruppen.
- Bei ungleicher Gruppengenauigkeit sind die Vorhersagen historisch benachteiligter Gruppen ungenauer.
- Individuelle Ungleichheiten schließlich treten zwischen ähnlichen Individuen auf, bei denen sich lediglich die Gruppenzugehörigkeit unterscheidet.
Genau oder gerecht – geht beides?
Aus den vorgestellten vier Arten von Diskriminierung lässt sich eine Vielzahl von Gerechtigkeitsdefinitionen ableiten. In seinem Tutorial auf der FAT*-Konferenz 2018 beschreibt Arvind Narayanan 21 solcher möglichen Definitionen und das Dilemma zwischen ihnen. Denn beim beschriebenen Problem akkurater Daten, die historische Verzerrungen wiedergeben, muss zwangsläufig zwischen verschiedenen Zielen abgewogen werden.
Im Extremfall muss ein Algorithmus (oder zunächst dessen Designer:in) zwischen Genauigkeit und Gerechtigkeit wählen. Nehmen wir beispielsweise einmal an, vier Personen bewerben sich auf zwei Stellen. Davon sind zwei weiblich und besser qualifiziert als die beiden anderen, männliche Bewerber. Nun können entweder die beiden Bewerberinnen angestellt werden oder die best-qualifizierte Frau und der best-qualifizierte Mann. Es muss also Genauigkeit und Geschlechterparität abgewogen werden. In den allermeisten Fällen gibt es allerdings mehr als diese zwei Optionen und ein Kompromiss zwischen den Extremen kann gefunden werden. Wichtig ist an dieser Stelle, dass es sich nicht objektiv bestimmen lässt, welche Option dabei gewählt werden soll, da alle in gewisser Weise optimal sind (ein sogenanntes Pareto-Optimum). Sub-optimale Optionen, im Beispiel etwa die Anstellung der beiden Männer, werden nicht betrachtet. Nun bedarf es einer ethischen Abwägung zwischen den allesamt mathematisch optimalen Optionen.
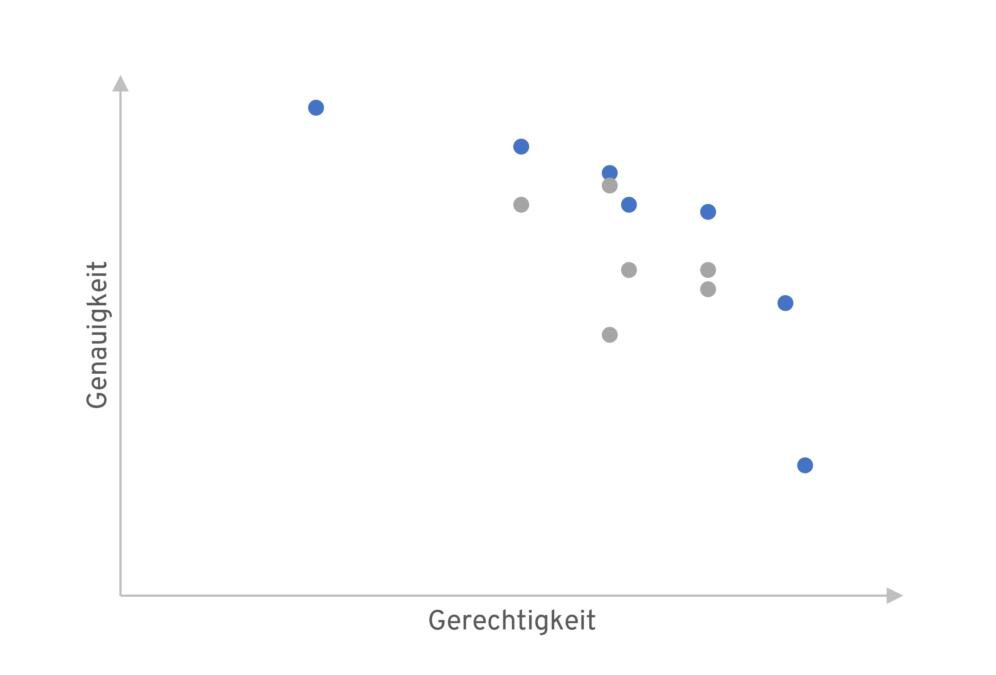
Somit steht jeder Entscheider, jede Entscheiderin, ob Mensch oder Maschine, vor dem Problem der Abwägung zwischen Genauigkeit und Gerechtigkeit. In der Tat ist das nicht die einzige notwendige Abwägung, sondern auch zwischen verschiedenen Gerechtigkeitsdefinitionen besteht ein solcher Konflikt. Das wurde bereits am Konflikt der Definitionen von ProPublica und Northpointe deutlich. Und es lässt sich auch mathematisch beweisen, dass nicht alle Definitionen gleichzeitig erfüllt werden können, wenn sich das Vorkommen von Strafrückfälligkeit zwischen den beiden Gruppen unterscheidet.
Moralische Maschinen
Wie kann also mit diesem Konflikt zwischen Genauigkeit und (verschiedenen) Gerechtigkeitsdefinitionen bei automatisierten Entscheidungen umgegangen werden? Einen interessanten Ansatz zur Diskussion eines ähnlich komplexen ethischen Dilemmas bietet die Moral-Machine-Studie des MIT Media Labs. Studienteilnehmende sollen dabei verschiedene Unfallsituationen eines autonomen Autos beurteilen. Es geht darum zu entscheiden, wie das Auto sich verhalten soll, wenn in einer Unfallsituation die Insassen nur überleben können, wenn Fußgänger:innen getötet werden oder umgekehrt. Und was, wenn die Fußgänger:innen über eine rote Ampel gegangen sind? Was, wenn ein Insasse schwanger ist? Die Studie zeigt unter anderem, dass Menschen aus verschiedenen Kulturen diese Entscheidungen unterschiedlich treffen.
Psychologische Forschung hat ergeben, dass Menschen auch Gerechtigkeit unterschiedlich wahrnehmen. Solche Unterschiede existieren zwischen sozialen Kontexten, Geschlechtern, Kulturen und Menschen mit verschiedenen Persönlichkeiten. Hinzu kommt, dass Einschätzungen darüber, welche Gerechtigkeitsdefinition einer anderen vorzuziehen ist, sich nicht pauschal treffen lassen, sondern vom Kontext und der konkreten Fragestellung abhängig sind. Daraus lässt sich schlussfolgern, dass empirische Erhebungen von Gerechtigkeitswahrnehmung, mit einem Werkzeug ähnlich wie die Moral Machine, von großem Interesse sein dürften. Denn statt die Abwägung von Genauigkeit und Gerechtigkeit den Entwickler:innen zu überlassen, könnte so auf demokratische Weise eine Balance gefunden werden und dadurch möglicherweise sogar die Akzeptanz der damit entwickelten Algorithmen gesteigert werden.
Tatsächlich gibt es schon einige Studien, die sich der empirischen Erforschung von Gerechtigkeitswahrnehmungen widmen. Allerdings ist diese Herangehensweise auch nicht ohne Probleme. Denn wenn die Mehrheit entscheidet, was gerecht ist, entscheidet sie sich dann möglicherweise für eine Gerechtigkeitsdefinition, die der Minderheit schadet? Wie lassen sich die Nuancen verschiedener Definitionen überhaupt vermitteln, bevor Laien beispielsweise in einer Umfrage zwischen den Definitionen abwägen müssen? Wie gehen wir damit um, wenn die Teilnehmenden einer solchen Studie viele verschiedene mögliche Abwägungen wählen und keine klaren Favoriten entstehen?
Trotz zahlreicher Wege, auf denen sich Diskriminierung in automatisierte Entscheidungen einschleichen kann, können Maschinen fair sein. Doch Gerechtigkeit kann nicht als Plugin aktiviert werden, denn verschiedene Definitionen von Gerechtigkeit stehen im Konflikt. Empirische Erhebungen von Gerechtigkeitswahrnehmungen liefern einen interessanten Ansatz zur Diskussion dieses Dilemmas.



Vielen, vielen Dank für diesen spannenden Artikel!!
Leider schließen sich „Gerechtigkeiten“ manchmal wie beschrieben direkt aus, im Wahljahr werden wir z.B. wieder Debatten über „Leistungsgerechtigkeit“ vs. „Verteilungsgerechtigkeit“ hören. Dieses inherente System-Problem (not a Bug, simply a feature) dürfen wir nicht als menschliches Problem sehen, sonst landen wir im technokratischen „der Algorithmus wird’s fehlerfrei machen!“.
Leistung und Verteilung haben Grenzen. Übertreibe eines, und du hast keine Zivilisation mehr.
Verteilung hat allerdings mehr Richtungen als Leistung… während Leistung sich auch schnell relativiert – ist es eine „Leistung“ für IQ 180 ein paar Klötzchen zusammenzuschieben?
Hier ist viel Raum für Selbstzersztörung :).
> Dieses inherente System-Problem (not a Bug, simply a feature) dürfen wir nicht als menschliches Problem
> sehen, sonst landen wir im technokratischen „der Algorithmus wird’s fehlerfrei machen!“.
Dieser Satz ist m.E. Unlogisch weil falsch. Solche Probleme sind System-Probleme die ein Menschliches sind weil es das Menschliche „System“ betrifft (das weniger über viele Bestimmen z.B.) Ein Programm ändert nichts daran denn es wird von Menschen geschaffen und von anderen Beauftragt – die alle ihre Eigenen Ziele und Vorstellungen verfolgen. Die Technik war NIE besser als die Menschen selbst.
Und ganz allgemein finde ich das man Werte wie Moral, Ethik oder Gerechtigkeit einer Maschine heute weder erfolgreich beibringen kann noch das man es sollte. Wie der Artikel ja zeigt wäre die Maschine nur so gut wie die Daten die sie bekommt und der Algorithmus der sie verarbeiten soll. An einem von beiden kann immer „gedreht“ werden um erwünschte Ergebnisse zu erhalten und ich meine das wird wohl auch gemacht.
Dann kann man gleich einen Menschen entscheiden lassen. Denn das ist die eigentliche Krux dabei. Wenn Menschen ihre Entscheidungen an Maschinen delegieren wird diese nie besser – nur schneller und falscher.
Das ist bequem weil man dann sagen kann „die Maschine war’s“ aber eigentlich wirft das eher ein Schlechtes Licht auf jene die sie anschafften. Und das ist das eigentliche Problem heute: Wem Werte wie Moral, Ethik und Gerechtigkeit selbst fehlen der kann sie nicht durch eine Maschine erlangen. Statt das eigene Unvermögen damit zu kaschieren muß jeder Entscheider/Mensch lernen die Werte selbst erst ein mal zu verinnerlichen.
Dann braucht man auch die Maschine dafür nicht mehr!
Aber es wird immer jene geben die ihren Eigenen Vorwand, Sündenbock, Gott-ersatz schaffen wollen…
Vielen Dank für den sehr interessanten Artikel! Mir stellt sich allerdings die Frage, wieso Sie nach dem Artikel zu dem Schluss kommen „[Trotzdem][…], können Maschinen fair sein.“ Müsste es nicht vielmehr heißen: „[Trotzdem] können Maschinen spezifische Gerechtigkeitsvorstellungen exekutieren“. Da sich innerhalb der Gesellschaft unterschiedliche Gerechtigkeitsauffassungen befinden, braucht es m.E.n. notwendigerweise einen gesellschaftlichen Aushandlungsprozess, welcher eine Sensibilität für das Dazwischen, zwischen den Gerechtigkeitsauffassungen schafft. Algorithmen/Daten kennen aber kein „dazwischen“, und sind somit dafür ungeeignet.
Guter Artikel. Leider aber spricht der Autor viel von Gerechtigkeit ohne zu definieren, was er darunter versteht bzw was im Kontext seines forschungsfeldes darunter verstanden wird.
Das ist jedoch relevant, um tatsächlich bestimmen zu können was gerechte oder ungerechte Entscheidungen sind. Ansonten fehlen die anhaltspunkte dafür und bleibt eine Bauchentscheidung
Dass Maschinen fair sein könnten kann nach dem Artikel oben gar nicht so gesagt werden. Dass sie unter bestimmten Bedingungen „fairer“ als Menschen sein könnten, das will ich nicht bestreiten.
Maschinen sind nur „fair“ oder besser „korrekt“ nach den Lerndaten innerhalb der Fehlerschranke, die man zugelassen hat. Um unfair sein zu können müssten Maschinen eine Absicht haben. Fair in diesem Sinn ist kein Ausdruck, der mit Maschinen assoziiert werden kann.
Mehr noch, aufgrund des Funktionsprinzips (surjektive Abbildung einer großen Menge an Eingangsparametern auf wenige Ausgangsparameter) muss die Maschine „verallgemeinern“. Das gilt selbst dann, wenn man Forderungen nach Fairness in den Lerndaten und Bewertungsfunktionen berücksichtigt und voraussetzt, dass Minderheiten nicht in den Lerndaten diskriminiert werden.
Das ist prinzipbedingt, unvermeidlich, ja bis auf die Fehler geradezu das, was wir von der Maschine wollen. Für Menschen äußert sich das jedoch oftmals wie ein unerklärbares Vorurteil. Ich gehe davon aus, dass auch überprüfbare AI daran nichts ändern kann (…)
TL;DR: Nicht die Maschine ist verantwortlich. Der Betreiber ist verantwortlich.
Man sagt die Maschine sei unfair, weil die Werbung sagt oder suggeriert, die Maschine sei fair. Zudem ersetzen die Maschinen Prozesse, die auch oft schon nicht mehr „fair“ sein können, weil ausführende Menschen zumeißt nur Regeln, Routine, oder sogar Gusto befolgen.
Eher so…
Gerechtigkeit ist keine „Definitionsfrage“, sondern setzt eine Übereinkunft voraus. Nur solange diese Übereinkunft besteht, gibt es Gerechtigkeit. Deswegen ändert sich auch das, was wir als gerecht empfinden.
Beispiel: Gem. § 1619 ist Kinderarbeit in Deutschland in dem dort bestimmten Umfang Pflicht! Das weiß nur niemand mehr. Deshalb wir dieser Paragraf als „ungerecht“ empfunden. Hier ist der Konses verloren gegangen. So ändert sich das Gerechtigkeitsempfinden.