Ein kürzlich veröffentlichtes Patent gibt Aufschluss darüber, wie Facebook seine Nutzer auf Basis ihrer Daten in soziale Klassen einteilen will. Demnach unterscheidet das Unternehmen in „Arbeiterklasse, Mittelklasse und Oberschicht“. Wie sich aus dem Patent schließen lässt, geht es davon aus, seine Nutzer nicht selbst zu klassifizieren, sondern lediglich deren Zugehörigkeit zu bereits existierenden sozioökonomischen Gruppen zu prognostizieren.
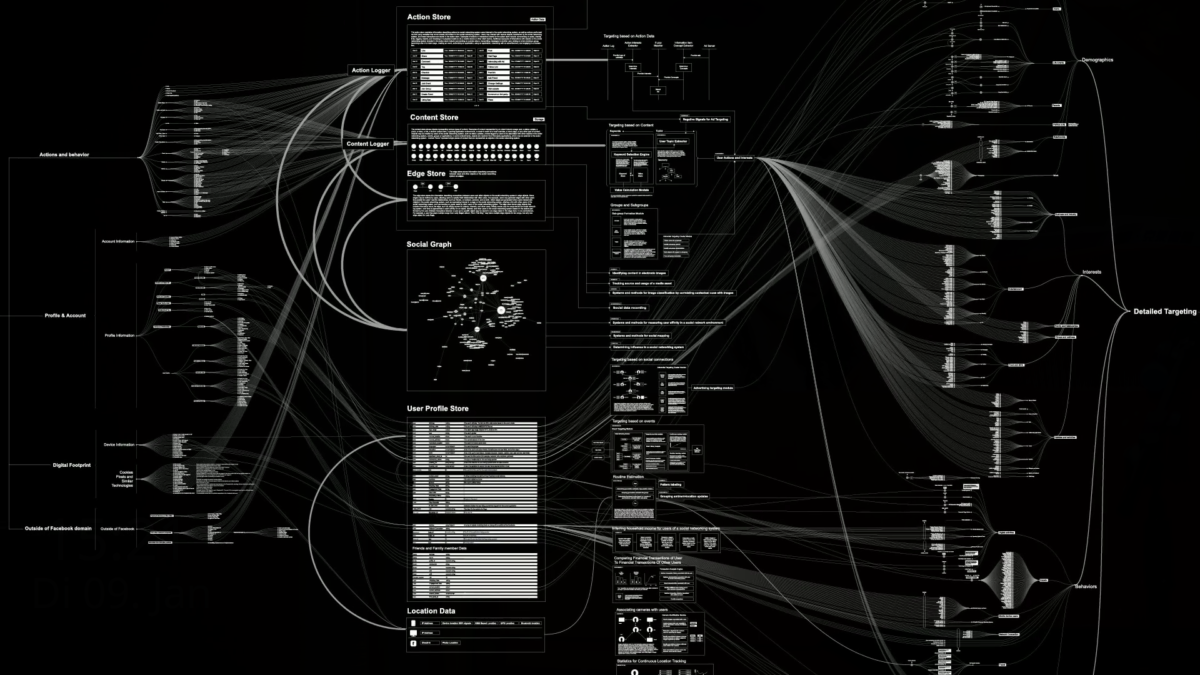
In die Big-Data-Analyse fließen unter anderem folgende Informationen ein: demographische Informationen wie Alter, Geschlecht, Ethnie, Bildungsstand, Wohnort; Art und Anzahl der internetfähigen Geräte, die jemand besitzt; Internetnutzung; Reiseaktivität; Haushaltsinformation wie Anzahl der Fahrzeuge oder Größe der Wohnung. Informationen über seine Nutzer, die Facebook nicht selbst sammeln oder erschließen kann, kauft das Unternehmen bekanntermaßen von Datenhändlern wie Oracle oder Acxiom.
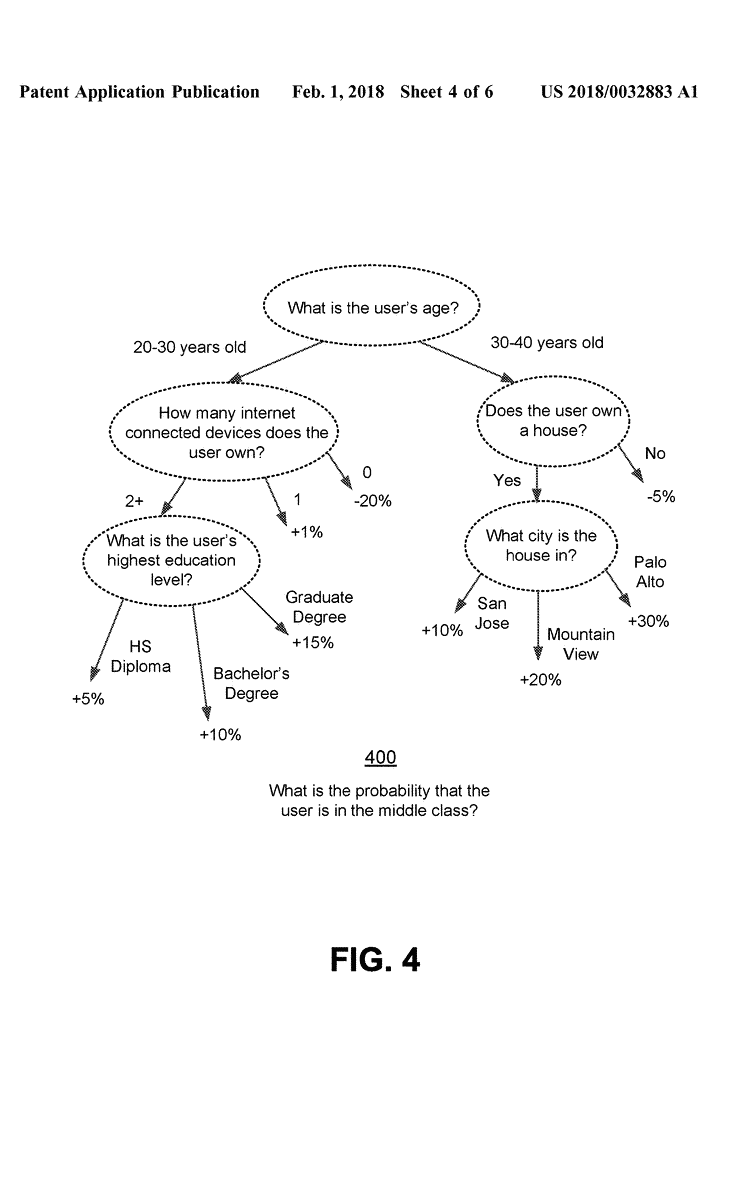
Je nach Alter könnten verschiedene Indikatoren unterschiedlich stark gewertet werden. In einem Beispielfall beschreibt Facebook, dass bei 20- bis 30-Jährigen beachtet werden könnte, wie viele internetfähige Geräte sie besitzen, während bei 30- bis 40-Jährigen stärker einfließen könnte, ob sie ein Haus besitzen und in welcher Region es sich befindet. Dem Patent zufolge könnten bei der Analyse Machine-Learning-Systeme zum Einsatz kommen, um die Zuordnung zu optimieren. Die Methode könne auch einen Zuverlässigkeitswert liefern, der Auskunft darüber gibt, wie gut die Vorhersagequalität ist. Mehr Daten würden dazu führen, dass die Trefferquote steige.
Besseres Microtargeting
Der Zweck des Verfahrens ist nach Facebooks primär ökonomischen Logik schlüssig: Das Unternehmen möchte damit seine Fähigkeiten zum Microtargeting weiter verbessern. Es verdient den Großteil seines Geldes damit, dass politische und kommerzielle Akteure ihre Inhalte möglichst zielgenau an gewünschte Zielgruppen ausspielen können. Aus dem Patent:
Zu den Inhalten können gesponserte Inhalte gehören, die Drittparteien dem Online-System zur Verfügung stellen. Eine solche Drittpartei ist beispielsweise eine Einheit, die Produkte oder Dienste anbietet und die Aufmerksamkeit ausgewählter Nutzer des Online-Systems, die zu einer bestimmten sozioökonomischen Gruppe gehören, hierfür steigern möchte. Durch die Prognose der sozioökonomischen Gruppe kann das Online-System der Drittpartei helfen, den ausgewählten Nutzern die gesponserten Inhalte zu präsentieren. Drittparteien ist es so möglich, ihre Produkte oder Dienste effektiv zu bewerben und das Online-System kann seinen Nutzern ein besseres Nutzungserlebnis ermöglichen, indem Inhalte generiert werden, die sie entsprechend ihrer vorhergesagten sozioökonomischen Gruppe mehr interessieren.
Microtargeting bei Facebook: Klasse, Ethnie, Psyche
Die Kategorisierung nach sozioökonomischen Kriterien ist in der Datenbranche kein unbekanntes Prinzip. Datenhändler wie Oracle oder Acxiom bieten explizit Informationen über Millionen Menschen in diesen Kategorien an. Letztere sind zudem dafür bekannt, dass sie kommerziell weniger attraktive Menschen in der Kategorie „waste“ („Müll“) sammelte.
Ob die hier patentierte Methode in dieser Form bereits im Einsatz ist, bleibt unklar. Unabhängig davon macht sie die grundsätzliche Logik des datenbasierten Microtargeting sehr gut anschaulich. Dass Facebook umfangreiche Analysen vornimmt, um seine Nutzer in vermarktbare Kategorien zu sortieren, ist bekannt. In den USA gibt es immer wieder Diskussionen darum, dass der Konzern Menschen auch nach „ethnischer Affinität“ kategorisiert und es Werbenden ermöglicht, sie anhand dieses Kriteriums anzusprechen oder auszuschließen. Erst im vergangenen Jahr war zudem publik geworden, dass Führungskräfte des Unternehmens die Qualität der zielgerichteten Werbung auf Facebook damit anpriesen, dass Werbekunden emotional verletztliche Jugendliche identifizieren und in den Momenten erreichen könnten, in denen diese sich besonders „wertlos“ fühlen.
[via futurzone.at]