
Der gegenwärtige Trend, Künstliche Intelligenz (KI) zunehmend in Online-Suchmaschinen einzubauen, dürfte weitreichende Folgen für die Informationsvielfalt im Internet haben. Unabhängig von der Qualität automatisiert generierter KI-Antworten droht, dass sich viele Nutzer:innen mit ihnen zufrieden geben und nicht mehr auf die eigentlichen Quellen klicken – sofern sie diese überhaupt zu Gesicht bekommen. Der wegbrechende Traffic könnte wiederum das bestehende Geschäftsmodell vieler Medien gefährden, die sich bislang über Werbung auf ihren Online-Auftritten finanzieren.
Das sind die Kernaussagen eines aktuellen Gutachtens des Informationswissenschaftlers Dirk Lewandowski von der Hochschule für Angewandte Wissenschaften Hamburg (HAW), erstellt im Auftrag der Direktorenkonferenz der Landesmedienanstalten. Näher untersucht hat der Wissenschaftler die Angebote von Google und Bing, die inzwischen KI-Suchergebnisse prominent einblenden, sowie die KI-Chatbots ChatGPT und Perplexity. Die Datenerhebung fand im Mai 2025 statt und stellt eine „Momentaufnahme in einem sich schnell entwickelnden Feld“ dar, betont Lewandowski.
Einbrechende Klick-Zahlen
Dass sich die Informationslandschaft im Netz drastisch verändern dürfte, hatte sich bereits abgezeichnet, seit generative KI vor rund drei Jahren im großen Stil im Massenmarkt ausgerollt wurde. Seitdem verzeichnen viele Verlage teils erhebliche Einbrüche in den Klickzahlen und warnen vor dem „Ende des Internets, wie wir es kennen“, titelte etwa ein Kommentar auf heise online. Erste Studien zu diesen Effekten bestätigen den Eindruck: Dem US-amerikanischen Pew Research Center zufolge würden Nutzer:innen nur etwa halb so oft auf die Links zu den dazu gehörigen Suchergebnissen klicken, wenn ihnen KI-Zusammenfassungen angezeigt würden. Der bisherige Deal, Inhalte gegen Reichweite zu tauschen, wackelt beträchtlich.
Dabei starten die KI-Firmen von unterschiedlichen Ausgangspunkten. Alphabet und Microsoft, denen Google respektive Bing gehören, integrieren ihren KI-Ansatz in ihre etablierten Suchmaschinen und blenden die Ergebnisse von Anfragen dort ein. Chatbots wie ChatGPT setzen hingegen auf Konversationen mit ihren Nutzer:innen. KI-generierte Antworten stehen entsprechend im Mittelpunkt ihrer Produkte. Diese Richtung schlagen nun offenbar auch traditionelle Suchmaschinen ein. Zuletzt hat etwa Google damit begonnen, Nachfragen und Unterhaltungen mit den Suchergebnissen zu erlauben. Einfließen konnte dies in das aktuelle Gutachten allerdings nicht mehr.
Mehr Chats, weniger Quellenbesuche
Ein stärkerer Fokus auf chatbasierte Systeme dürfte die „Bedeutung der Quellen noch weiter einschränken“, heißt es in der Studie. Quellen dienten dann nur noch der vertiefenden Beschäftigung mit einem Thema, während sich viele Nutzer:innen mit den KI-Antworten zufriedengeben und allenfalls beim Bot weiter nachfragen.
Zugleich würden KI-basierte Systeme jedoch die sogenannte „Task Frontier“ erweitern. Hier fallen die Suche nach Informationen und deren anschließende Nutzung nahtlos zusammen. Solche Systeme könnten die Bearbeitung komplexer Aufgaben übernehmen, die sich mit bisherigen Suchsystemen nicht bearbeiten ließen, versprechen zumindest die KI-Anbieter. Wer braucht da noch Quellen?
Insgesamt verändere sich damit die Rolle von Suchmaschinen, die sich zunehmend von ihrer bisherigen Vermittlungsrolle verabschieden und „eigenständige Informationsobjekte“ erstellen würden. Daraus dürften sich medienrechtliche Fragen nach einem passenden Regulierungsansatz ergeben, was „juristisch zu betrachten und zu beantworten sein“ werde, schreibt Lewandowski.
Im Fluß ist auch die Frage, unter welchen Bedingungen und aus welchen Informationen diese Wissenshäppchen erstellt werden. Anfangs haben die KI-Firmen erst einmal ohne Rücksicht auf Urheberrecht oder Privatsphäre alles aus dem Netz abgezogen, was nicht niet- und nagelfest war, um damit ihre Systeme zu trainieren. Klagen folgten prompt. Zwar ist bis heute nicht endgültig geklärt, ob und in welchem Ausmaß sie dabei tatsächlich Recht gebrochen haben – aber neben außergerichtlichen Einigungen musste etwas Tragfähiges her.
Lizenzmodelle im Aufwind
In den vergangenen Jahren haben viele Verlage, aber auch Online-Dienste wie Reddit Verträge mit KI-Anbietern geschlossen. Gegen Bezahlung liefern sie mal mehr, mal weniger qualitativ hochwertiges Traningsmaterial. In Deutschland hat der Springer Verlag, der unter anderem die Bild, Welt und Politico herausgibt, eine Vorreiterrolle eingenommen. Seit Ende 2023 soll die Partnerschaft mit OpenAI „das Nutzungserlebnis mit ChatGPT um aktuelle und verlässliche Inhalte zu einer Vielzahl von Themen bereichern“, bewirbt der Verlag die Zusammenarbeit.
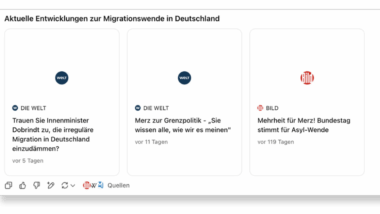
Das schlägt sich entsprechend auf der inhaltlichen Ebene nieder, wie das KI-Gutachten am Rande illustriert. Bisweilen blendet ChatGPT unterhalb der Antworten weiterführende Links ein, wenn es um besonders „aktualitätsrelevante Inhalte“ geht. Erwartungsgemäß handelt es sich im deutschsprachigen Raum sehr häufig um Angebote des Axel-Springer-Verlags. Die Folge: Interessierte Nutzer:innen können sich dann vor allem bei Bild oder Welt weiter darüber informieren, wie die Merz-Regierung etwa mit Themen wie Migration umgeht.
Generell bestehe bei solchen Lizenzvereinbarungen die Gefahr, schreibt Lewandowski, dass Suchsysteme nur die Inhalte eines oder weniger Anbieter in einem Themenfeld für die Generierung ihrer KI-Antworten verwenden. Letztlich könnte sich auch das negativ auf die Angebotsvielfalt im Netz auswirken und den Trend der abnehmenden Zugriffszahlen und rückläufigen Werbeeinnahmen verstärken.
Dabei sei es fraglich, ob neue Geschäftsmodelle wie die Lizenzierung der Inhalte an KI-Anbieter die geringeren Einnahmen durch den Traffic-Einbruch ausgleichen könnten. „Sofern dies nicht gelingt, wird die Menge und/oder Qualität der produzierten Inhalte zurückgehen“, heißt es im Gutachten.
Untergejubelte Informationen
Im Datenbestand der KI-Firmen zunehmen dürfte hingegen der Anteil von Inhalte-Lieferanten, die nicht auf eine direkte Refinanzierung ihrer Inhalte angewiesen sind. Das können Nichtregierungsorganisationen, Verbände und ohnehin alle sein, die die öffentliche Meinung beeinflussen wollen. Gerne auch verdeckt: PR-Agenturen, Unternehmen, Lobby-Firmen, Parteien und Staaten wie Russland, die groß angelegte Desinformationsnetzwerke mit massenhaft produzierten Inhalten betreiben.
In jedem Fall sei mehr Forschung notwendig, betont das Gutachten mehrfach, etwa im Hinblick auf das Nutzerverhalten und die langfristigen Traffic-Auswirkungen von KI-Antworten auf die Refinanzierung von Online-Inhalten. Zumindest ein rechtliches Folgegutachten befinde sich bereits in der Vergabephase, sagte Eva Flecken, Direktorin der Medienanstalt Berlin-Brandenburg und Vorsitzende der Direktorenkonferenz der Landesmedienanstalten, gegenüber Tagesspiegel Background (€).
Dieses Folgegutachten solle untersuchen, welche Rolle Intermediäre bei der Vielfaltssicherung spielen müssen; insbesondere stellten sich Fragen rund um Transparenz und Haftung. Außerdem habe der Digital Services Coordinator um eine Stellungnahme gebeten; also jene Stelle, die in Deutschland die Umsetzung des EU-Gesetzes über digitale Dienste (DSA) überwacht. Das Thema könnte bei der EU-Kommission landen.



Schreibe eine Ergänzung!