Eine „Paywall“, also eine technische Bezahlschranke, kann bei der Recherche sehr störend sein, wenn man beispielsweise auf der Suche nach wissenschaftlichen Untersuchungen oder Zeitschriftenbeiträgen ist. Zugang zu den Inhalten von tausenden Open-Access-Inhalten bietet jedoch seit einiger Zeit eine praktische Browser-Erweiterung für Chrome und Firefox mit dem Namen „Unpaywall“ (Chrome Extension, Firefox Extension). Anders als bei Alternativen wie Sci-Hub wird hier versucht, möglichst keine Rechte zu verletzen. Stattdessen werden bei Unpaywall diejenigen akademischen Open-Access-Papiere im Volltext gesucht und angeboten, die Forscher und Wissenschaftler selbst in akademische Repositories hochladen.
Interessant ist das Angebot nicht nur für Wissenschaftler, sondern insbesondere für Menschen außerhalb der Universitäten oder in Staaten mit wenig Zugang zu weltweiter akademischer Literatur. Denn wer in Forschungseinrichtungen arbeitet, hat oft die Möglichkeit, sich in deren Bibliotheken Inhalte zu verschaffen, die hinter Paywalls versteckt sind. Aber gerade für Menschen außerhalb dieser Institutionen ist Unpaywall nutzbringend, weil sie diese Zugänge nicht so leicht bekommen können.
Jason Priem, der zusammen mit Heather Piwowar die Idee zu Unpaywall hatte, fasst das Ziel so zusammen:
We want to do just one thing really well: instantly deliver legal, open-access, full text as you browse.
Wir wollen nur eine Sache wirklich gut machen: beim Browsen sofort legale, vollständige Open-Access-Texte ausliefern.
Wer nach wissenschaftlichen Papieren sucht und auf eine Paywall stößt, kann mit einem einfachen Klick und kostenlos die vollständige Version des Beitrags als pdf-Datei lesen. Die Technik ist dem Open Access Button (mit der oaDOI-Schnittstelle) entlehnt und erlaubt den Zugriff auf etwa zehn Millionen wissenschaftliche Beiträge.
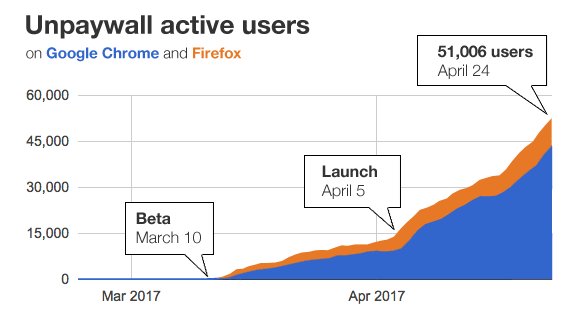
Dahinter steht Impactstory, eine von Stiftungen unterstützte Non-Profit-Organisation, die auf quelloffene Software setzt. Die erste Version von Unpaywall wurde am 5. April freigegeben und war in den folgenden Tagen schon von Tausenden heruntergeladen worden. Die Browser-Extension ist dabei denkbar einfach benutzbar und datensparsam in dem Sinne, dass keine personenbezogenen Daten abgefragt oder gespeichert werden. Sie kann also unpersonalisiert genutzt werden.
Als Alternative für eine automatische Open-Access-Suche gibt es außerdem noch den Wikipedia-OAbot, der bei den Referenzen auf Wikipedia-Seiten ansetzt und die zugehörigen Open-Access-Papiere sucht.