Aus digitalen Aufzeichnungen des menschlichen Verhaltens lassen sich individuelle Eigenschaften und Einstellungen ableiten. Das ist das Ergebnis einer Studie an der Cambridge University. Es reicht, die „Likes“ von Facebook-Profilen zu betrachten, um sehr persönliche Dinge mit hoher Wahrscheinlichkeit vorherzusagen.
Ein Forscher-Team um den Psychologen Michal Kosinski hat ein Paper in der wissenschaftlichen Fachzeitschrift PNAS veröffentlicht: Private traits and attributes are predictable from digital records of human behavior (PDF):
We show that easily accessible digital records of behavior, Facebook Likes, can be used to automatically and accurately predict a range of highly sensitive personal attributes including: sexual orientation, ethnicity, religious and political views, personality traits, intelligence, happiness, use of addictive substances, parental separation, age, and gender.
Dazu haben sie auf myPersonality.org Facebook Likes und demografische Daten von 58.000 Freiwilligen gesammelt. Mit dieser Datenbasis können die Forscher mit statistischen Analyseverfahren aus den öffentlichen Likes von beliebigen Facebook-Profilen individuelle psycho-demografische Eigenschaften vorhersagen. Und zwar mit einer Genauigkeit von bis zu 95 Prozent. Im Einzelnen:
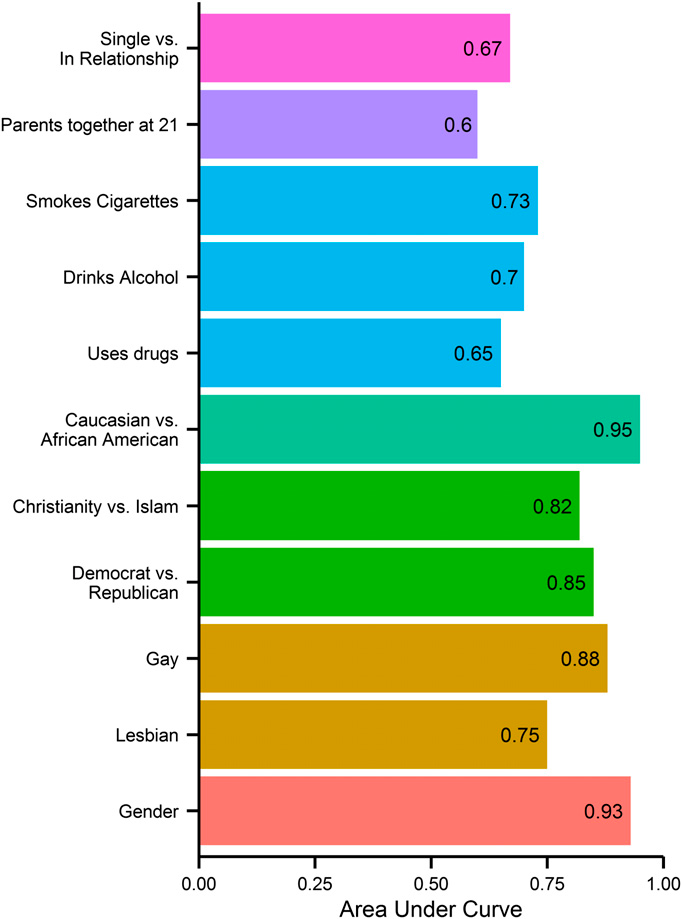
Das kann ganz automatisiert für Millionen von Menschen gemacht werden:
„What was traditionally laboriously assessed on an individual basis can be automatically inferred for millions of people without them even noticing,“ Kosinski says, „which is both amazing and a bit scary.“
Einen kleinen Selbst-Check für das eigene Facebook-Profil gibt es auf YouAreWhatYouLike.com. Bereits 2009 haben Studenten die sexuelle Orientierung anhand der Freunde von Facebook-Profilen herausgefunden.
Die Forscher glauben, dass diese Methode nicht auf Facebook Likes beschränkt ist, sondern aus vielen alltäglich anfallenden Daten detaillierte Persönlichkeits-Profile erstellt werden können:
We show that a wide variety of people’s personal attributes, ranging from sexual orientation to intelligence, can be automatically and accurately inferred using their Facebook Likes. Similarity between Facebook Likes and other widespread kinds of digital records, such as browsing histories, search queries, or purchase histories suggests that the potential to reveal users’ attributes is unlikely to be limited to Likes. Moreover, the wide variety of attributes predicted in this study indicates that, given appropriate training data, it may be possible to reveal other attributes as well.
Das könne dann zum Beispiel für personalisierte Werbung verwendet werden (wobei ich mich immer frage, wer ernsthaft Werbung sehen will). Oder missbraucht werden:
[…] The predictability of individual attributes from digital records of behavior may have considerable negative implications, because it can easily be applied to large numbers of people without obtaining their individual consent and without them noticing. Commercial companies, governmental institutions, or even one’s Facebook friends could use software to infer attributes such as intelligence, sexual orientation, or political views that an individual may not have intended to share. One can imagine situations in which such predictions, even if incorrect, could pose a threat to an individual’s well-being, freedom, or even life. Importantly, given the ever-increasing amount of digital traces people leave behind, it becomes difficult for individuals to control which of their attributes are being revealed. For example, merely avoiding explicitly homosexual content may be insufficient to prevent others from discovering one’s sexual orientation.
There is a risk that the growing awareness of digital exposure may negatively affect people’s experience of digital technologies, decrease their trust in online services, or even completely deter them from using digital technology. It is our hope, however, that the trust and goodwill among parties interacting in the digital environment can be maintained by providing users with transparency and control over their information, leading to an individually controlled balance between the promises and perils of the Digital Age.
Diese Forschung macht schön sichtbar, welche Macht in den Persönlichkeitsprofilen steckt, die alltäglich von uns erstellt werden. Das Problem bei diesen angeblich „pseudonymen“ Daten ist, das diese immer leichter einzelnen Personen zuordenbar und damit deanonymisierbar werden. Vor allem, je größer die Datenberge sind.
Als man Facebook diese Forschung präsentiert hat, war man dort nicht überrascht. Immerhin ist genau das deren Geschäftsmodell:
Science NOW contacted Facebook’s in-house social scientists about the work. The study’s results are „hardly surprising,“ the company contends in their official response. „On Facebook, people can share the things they like—like bands, brands, sports teams, public figures, etc. By using Login with Facebook on third party sites, people can take their Likes and interests with them around the web—to have more personalized experiences.“
„I am glad that Facebook is aware that likes allow predicting individual traits,“ Kosinski says. „I am afraid, however, that users [of Facebook and other online environments] do not realize that by ‚carrying around’ their likes, songs they listen to, Web sites they visit, and other kinds of online behavior, they are exposed to a degree potentially well beyond what they expect or would find comfortable.“
Es braucht also ein Bewusstsein, wie aussagekräftig solche Daten wirklich sind.